
The famous Turing Machine1)It was first described in Turing’s, “On Computing Machines with an Application to the Entscheidungsproblem,” in 1937 which can be downloaded here: https://www.cs.virginia.edu/~robins/Turing_Paper_1936.pdf. Also a very good book on the subject is Charles Petzold’s, “The Annotated Turing: A Guided Tour through Alan Turing’s Historic Paper on Computability and the Turing Machine.” was a thought experiment and, until recently did not physically exist 2)Yes, somebody has built one and you can see what Turing described here: https://www.youtube.com/watch?v=E3keLeMwfHY . When computer scientists talk about machines we don’t mean the, “lumps of silicon that we use to heat our offices,” (thanks Mike Morton for this wonderful quote), but, rather, we mean the software programs that actually do the computing. When we talk about Machine Learning we don’t think that the physical hardware actually learns anything. This is because, as Alan Turing demonstrated in the above paper, the software functions as a virtual machine; albeit, much more efficiently than creating a contraption with pens, gears, rotors and an infinitely long paper strip.
When I talk about, “feeding the machine,” I mean giving the program (the AI for General Staff is called MATE: Machine Analysis of Tactical Environments and the initial research was funded by DARPA) more data to learn from. Yesterday, the subject at machine learning school was Quatre Bras.
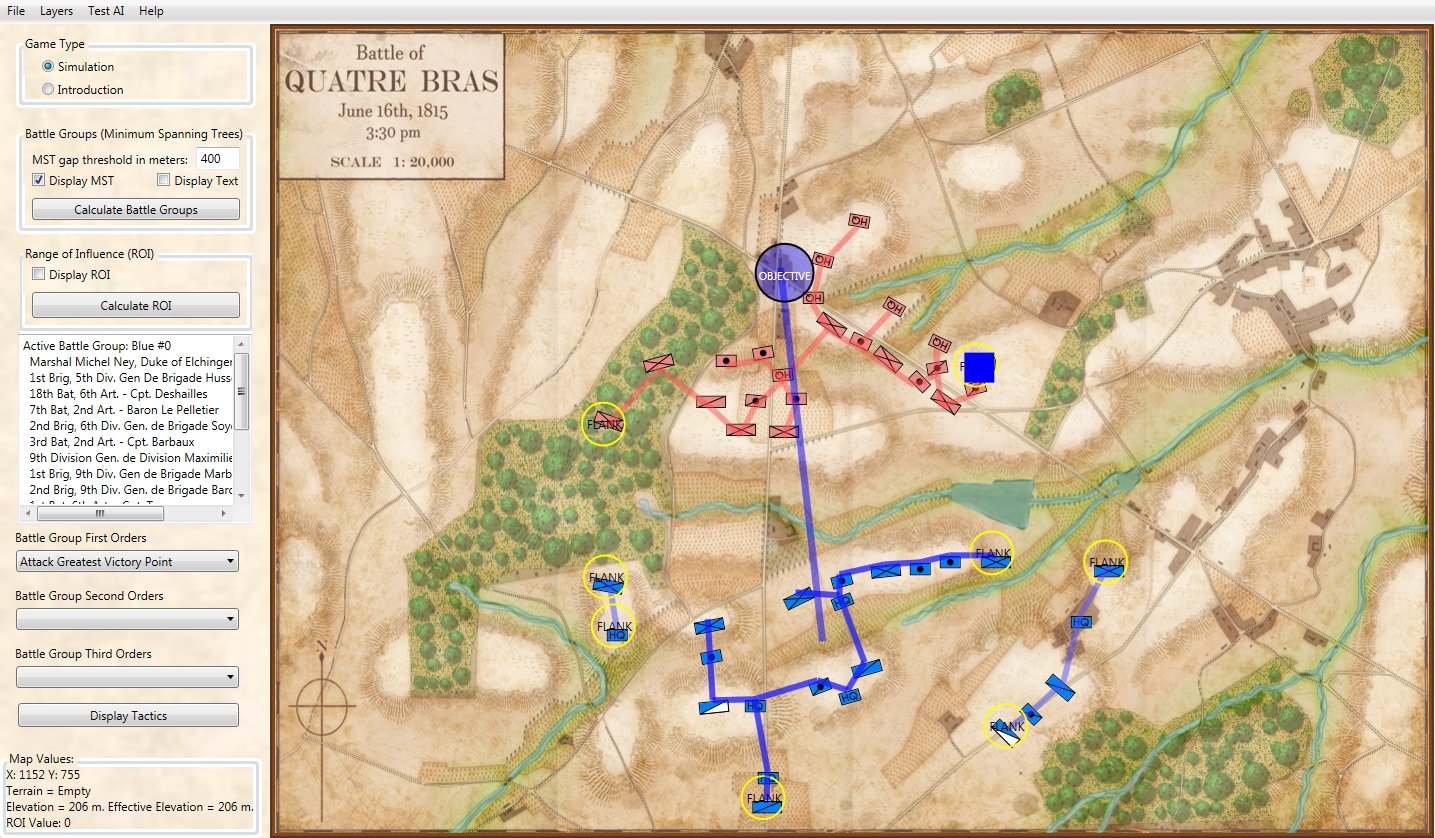
Screen shot of the General Staff AI Editor after analysis of Quatre Bras and calculating the flanking Schwerpunkt or point of attack (blue square). Click to enlarge.
The MATE tactical AI algorithms produce a plan of attack around a geographic point on the battlefield that has been calculated and tagged as the Schwerpunkt, or point where maximum effort is to be applied. In the above (Quatre Bras) scenario the point of attack is the extreme left flank of the Anglo-Allied (Red) army. I apply the ‘reasonableness test’ 3)Thank you Dennis Beranek for introducing me to the concept of ‘reasonableness test’. See https://www.general-staff.com/schwerpunkt/ for explanation and think, “Yes, this looks like a very reasonable plan of attack – a flanking maneuver on the opponent’s unanchored left flank – and, in fact, is a better plan than what Marhshal Ney actually executed.
It would be good at this point to step back and talk about the differences in ‘supervised’ and ‘unsupervised’ machine learning and how they work.
Supervised machine learning employs training methods. A classic example of supervised learning is the Netflix (or any other TV app’s) movie recommendations. You’re the trainer. Every time you pick a movie you train the system to your likes and dislikes. I don’t know if Netflix’s, or any of the others, use a weighting for how long (what percentage watched over total length of show) watched but that would be a good metric to add in, too. Anyway, that’s how those suggestions get flashed up on the screen: “Because you watched Das Boot you’ll love The Sound of Music!” Well, yeah, they both got swastikas in them, so… 4)Part of the problem with Netflix’s system is that they hire out of work scriptwriters to tag each movie with a number of descriptive phrases. Correctly categorizing movies is more complex than this.
Supervised machine learning uses templates and reinforcement. The more the user picks this thing the more the user gets this thing. MATE is unsupervised machine learning. It doesn’t care how often a user does something, it cares about always making an optimal decision within an environment that it can compare to previously observed situations. Furthermore, MATE is a series of algorithms that I wrote and that I adjust after seeing how they react to new scenarios. For example, in the above Quatre Bras scenario, MATE originally suggested an attack on Red’s right-flank. This recommendation was probably influenced by the isolated Red infantry unit (1st Netherlands Brigade) in the Bois de Bossu woods. After seeing this I added a series of hierarchical priorities with, “a flank attack in a woods (or swamp) is not as optimal as an attack on an exposed flank with clear terrain,” as a higher importance than pouncing on an isolated unit. And so I, the designer, learn and MATE learns.
My main concern is that MATE must be able to ‘take care of itself’ out there, ‘in the wild’, and make optimal decisions when presented with previously unseen tactical situations. This is not writing an AI for a specific battle. This is a general purpose AI and it is much more difficult to write than a battle specific AI. One of the key aspects of the General Staff Wargaming System is that users can create new armies, maps and scenarios. MATE must make good decisions in unusual circumstances.
Previously, I have shown MATE’s analysis of 1st Bull Run and Antietam. Below is the battle of Little Bighorn in the General Staff AI Editor:
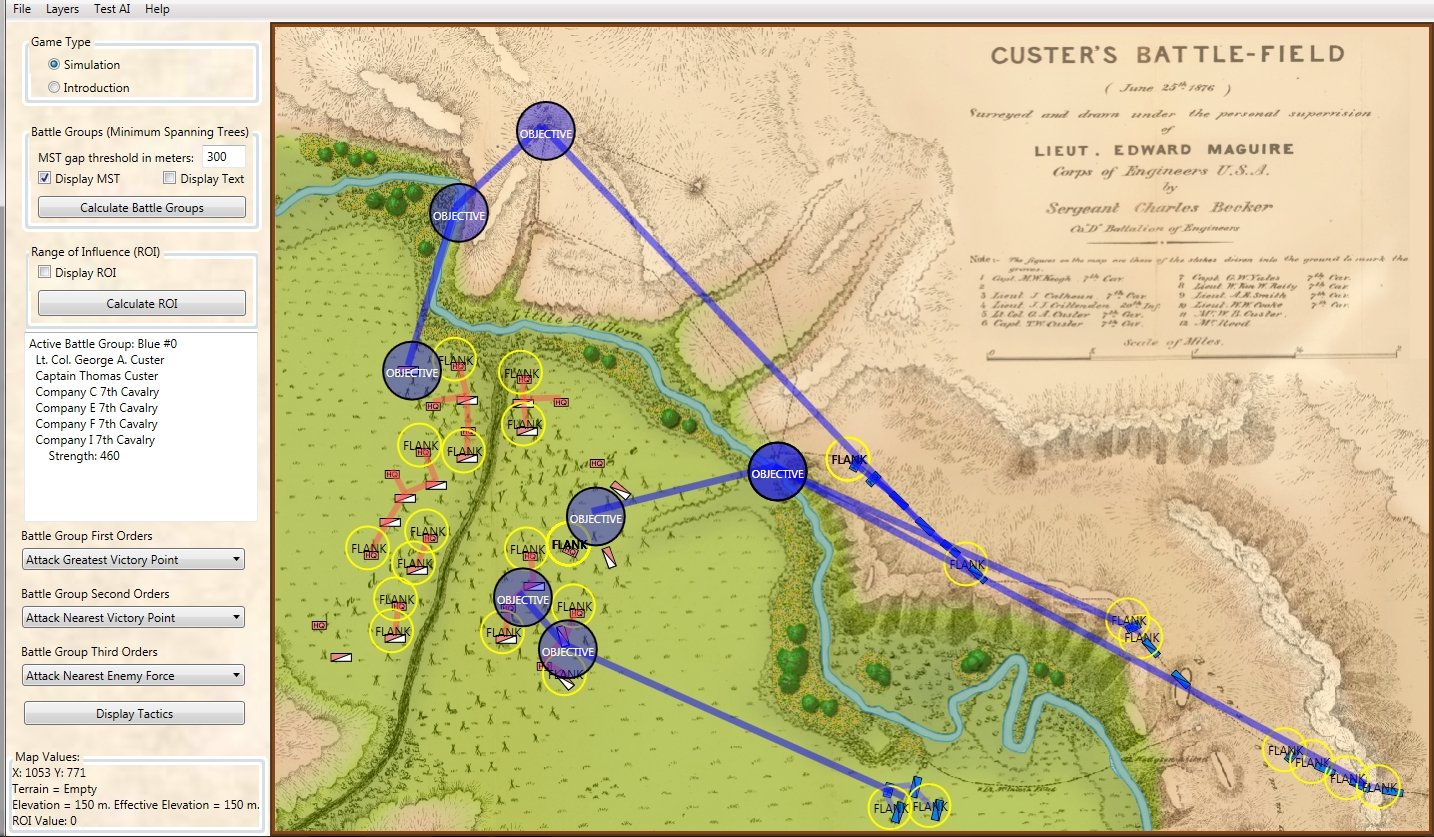
The battle of Little Bighorn in the General Staff AI Editor. Normally the MATE AI would decline to attack. However, when ordered to attack, this is MATE’s optimal plan. Click to enlarge.
I would like to expose MATE to at least thirty different tactical situations before releasing the General Staff Wargame. This is a slow process. Thanks to Glenn Frank Drover of Forbidden Games, Inc. for donating the superb Quatre Bras map. He also gave us maps for Ligny and Waterloo which will be the next two scenarios submitted to MATE. We still have a way to go to get up to thirty. If anybody is interested in helping to create more scenarios please contact me directly.
References
| ↑1 | It was first described in Turing’s, “On Computing Machines with an Application to the Entscheidungsproblem,” in 1937 which can be downloaded here: https://www.cs.virginia.edu/~robins/Turing_Paper_1936.pdf. Also a very good book on the subject is Charles Petzold’s, “The Annotated Turing: A Guided Tour through Alan Turing’s Historic Paper on Computability and the Turing Machine.” |
|---|---|
| ↑2 | Yes, somebody has built one and you can see what Turing described here: https://www.youtube.com/watch?v=E3keLeMwfHY |
| ↑3 | Thank you Dennis Beranek for introducing me to the concept of ‘reasonableness test’. See https://www.general-staff.com/schwerpunkt/ for explanation |
| ↑4 | Part of the problem with Netflix’s system is that they hire out of work scriptwriters to tag each movie with a number of descriptive phrases. Correctly categorizing movies is more complex than this. |
This is interesting Ezra. I share Kent’s question, how often does the AI recalculate the objective and the aim. This needs to be related to the time lag it takes for orders to halt a move to take effect.
Also how do you take account of imperfect knowledge of the enemy? Taking Little Bighorn as the example I believe Custer misjudged the strength and positions of their opponents. I suppose there is also the ego of the commander to throw into the mix.
Tim
I love questions like this!
First, there are many different ‘modes of play’ for General Staff (years ago a reviewer said one of my wargames had ‘almost infinite’ modes of play. What’s ‘almost infinite’? Infinity – 1? Anyway, among the options are:
The AI is calculated every turn. The length of a turn is set in the Scenario Editor. Turns at the battle of Antietam, for example, are set at 10 minutes. 1st Bull Run (much larger map) are set for 20 minutes.
Depending on the mode the AI may well have imperfect knowledge of the battlefield (as opposed to some AI that cheats… ahem Sid).
Yes, the AI has imperfect knowledge (or is playing with the same level of knowledge that the human player is).
I think one shortcoming of this approach is that it uses perfect knowledge of the enemy’s position. That situation never arises during this period as there is no aerial reconnaissance. Minor folds in the ground can hide numerous enemy formations. The Quatre Bras example illustrates this extremely well. At ground level, the wheat was taller than a man. The French had to grope their way towards the enemy. They had no real idea of the enemy’s strength or deployment. Ney actually did try to attack the Allied right with half of Foy’s division and that of Bachelu’s. However, by that time British troops had arrived on that part of the field and repulsed the attack. Ney also pushed on the Allied left, through and around the woods where he met with the most success because that was the weakest part of the Allied line. One always reinforces success which is what Ney did.
Finally, an attack on the Allied right as suggested by MATE would have been nearly impossible given the ponds and stream that would have to be negotiated. Even small streams were a huge impediment for troops during this period.
Attacking the Allied left, as Ney did, , given what could be seen in the field was the correct plan.
The AI plays by the same rules as the human. If you’ve selected Maximum Fog of War, then the AI is also hindered and will act accordingly.
The initial plan is very important.
How often will it adjust its strategy?
Faced with the plan falling apart, how long will it stick to the plan before developing a new plan?
If it readjusts continuously it could easily end up
being unstable.
Do you have a plan for the AI plan “encountering the enemy”?
Interesting, Ezra. I like the fact that you said it declined to attack. How did this attack turn out? A course of action that leads to a defeat (or maybe I should say predicts a defeat) is not a valid course of action.
perhaps more important, I presume MATE also analyzes the Sioux/Cheyanne COAs and comes up with a recommendation. What was that one?
Mike
Mike,
Funny, I hadn’t run that for Red. And, in fact, I was just thinking, “what are the odds that so far every attacker is Blue (or BLUEFOR)?” But, it’s true: 1st Bull Run, Antietam, Quatre Bras, Little Bighorn, Ligny, Waterloo. Isn’t that weird? I’ll take a look at this from Red’s perspective tomorrow.
First truth in advertising I’ve been in the AI field for 36 years (and a wargamer for longer) but I am from the symbolic reasoning side of the “house”. I have done ANN work in hybrids (neuro/fuzzy for the insurance and banking sectors).
My question has to do with explainability. As you are no doubt aware this has been a major topic in the field. AlphaGo can beat human opponents but it can not explain why it made a move.Can MATE because if so it is a really big deal.
Thanks for all your work I’m looking forward to the tool.
Yes, MATE can explain it’s work. Here is an example output: http://secureservercdn.net/184.168.47.225/b76.548.myftpupload.com/wp-content/uploads/2019/10/Battle-Group-1-analysis.jpg But I don’t think it’s a big deal. It’s just math.
As for AlphaGo (or Deep Blue): I’m not as impressed by Brute Force Search Engines as I should be. I admit that looking ahead 50 plys in an impressive feat of computing power but there’s not much intelligence there. But, in narrowly defined areas, like Go or Chess, can be quite effective.