
The famous Turing Machine1)It was first described in Turing’s, “On Computing Machines with an Application to the Entscheidungsproblem,” in 1937 which can be downloaded here: https://www.cs.virginia.edu/~robins/Turing_Paper_1936.pdf. Also a very good book on the subject is Charles Petzold’s, “The Annotated Turing: A Guided Tour through Alan Turing’s Historic Paper on Computability and the Turing Machine.” was a thought experiment and, until recently did not physically exist 2)Yes, somebody has built one and you can see what Turing described here: https://www.youtube.com/watch?v=E3keLeMwfHY . When computer scientists talk about machines we don’t mean the, “lumps of silicon that we use to heat our offices,” (thanks Mike Morton for this wonderful quote), but, rather, we mean the software programs that actually do the computing. When we talk about Machine Learning we don’t think that the physical hardware actually learns anything. This is because, as Alan Turing demonstrated in the above paper, the software functions as a virtual machine; albeit, much more efficiently than creating a contraption with pens, gears, rotors and an infinitely long paper strip.
When I talk about, “feeding the machine,” I mean giving the program (the AI for General Staff is called MATE: Machine Analysis of Tactical Environments and the initial research was funded by DARPA) more data to learn from. Yesterday, the subject at machine learning school was Quatre Bras.
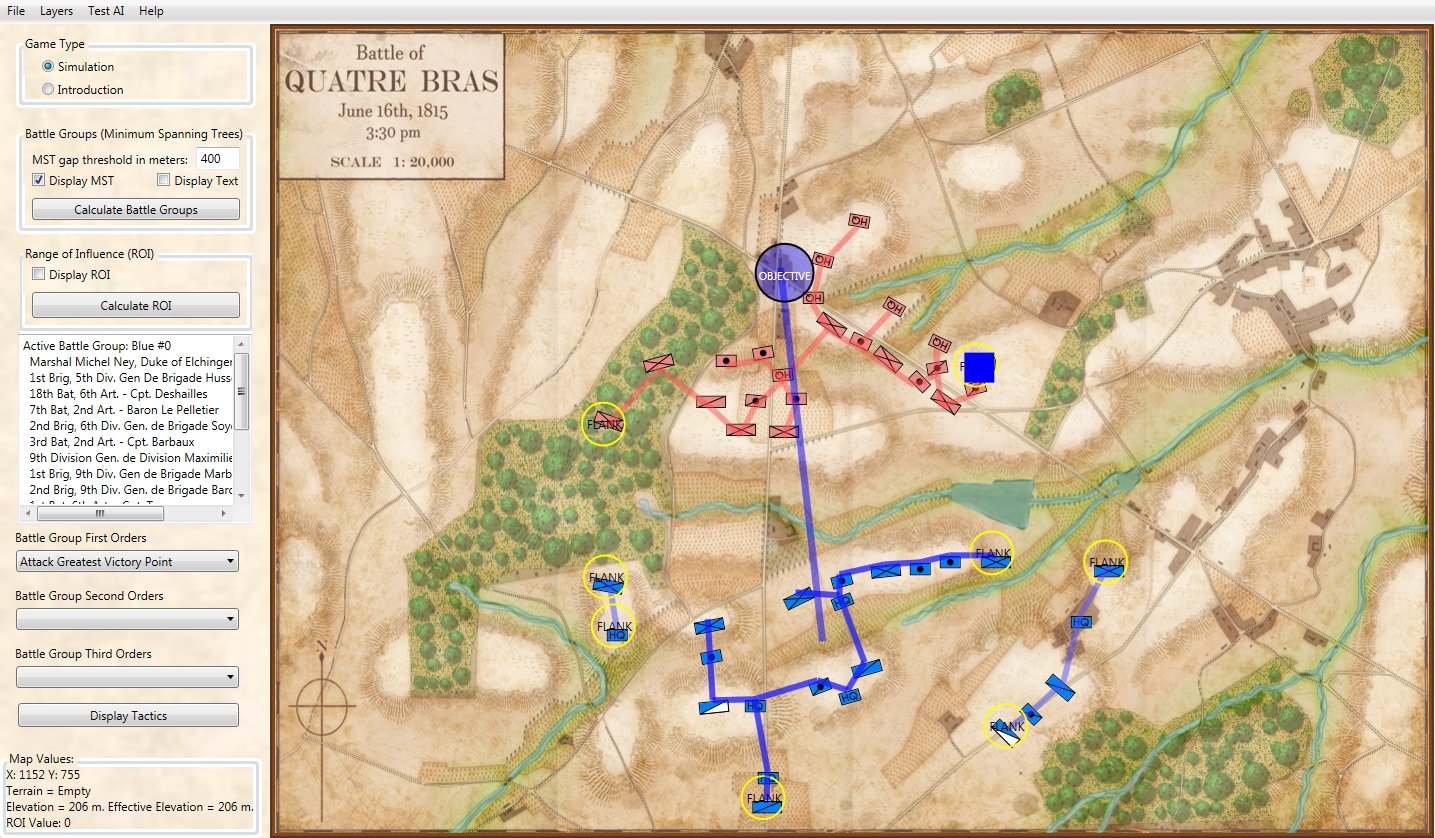
Screen shot of the General Staff AI Editor after analysis of Quatre Bras and calculating the flanking Schwerpunkt or point of attack (blue square). Click to enlarge.
The MATE tactical AI algorithms produce a plan of attack around a geographic point on the battlefield that has been calculated and tagged as the Schwerpunkt, or point where maximum effort is to be applied. In the above (Quatre Bras) scenario the point of attack is the extreme left flank of the Anglo-Allied (Red) army. I apply the ‘reasonableness test’ 3)Thank you Dennis Beranek for introducing me to the concept of ‘reasonableness test’. See https://www.general-staff.com/schwerpunkt/ for explanation and think, “Yes, this looks like a very reasonable plan of attack – a flanking maneuver on the opponent’s unanchored left flank – and, in fact, is a better plan than what Marhshal Ney actually executed.
It would be good at this point to step back and talk about the differences in ‘supervised’ and ‘unsupervised’ machine learning and how they work.
Supervised machine learning employs training methods. A classic example of supervised learning is the Netflix (or any other TV app’s) movie recommendations. You’re the trainer. Every time you pick a movie you train the system to your likes and dislikes. I don’t know if Netflix’s, or any of the others, use a weighting for how long (what percentage watched over total length of show) watched but that would be a good metric to add in, too. Anyway, that’s how those suggestions get flashed up on the screen: “Because you watched Das Boot you’ll love The Sound of Music!” Well, yeah, they both got swastikas in them, so… 4)Part of the problem with Netflix’s system is that they hire out of work scriptwriters to tag each movie with a number of descriptive phrases. Correctly categorizing movies is more complex than this.
Supervised machine learning uses templates and reinforcement. The more the user picks this thing the more the user gets this thing. MATE is unsupervised machine learning. It doesn’t care how often a user does something, it cares about always making an optimal decision within an environment that it can compare to previously observed situations. Furthermore, MATE is a series of algorithms that I wrote and that I adjust after seeing how they react to new scenarios. For example, in the above Quatre Bras scenario, MATE originally suggested an attack on Red’s right-flank. This recommendation was probably influenced by the isolated Red infantry unit (1st Netherlands Brigade) in the Bois de Bossu woods. After seeing this I added a series of hierarchical priorities with, “a flank attack in a woods (or swamp) is not as optimal as an attack on an exposed flank with clear terrain,” as a higher importance than pouncing on an isolated unit. And so I, the designer, learn and MATE learns.
My main concern is that MATE must be able to ‘take care of itself’ out there, ‘in the wild’, and make optimal decisions when presented with previously unseen tactical situations. This is not writing an AI for a specific battle. This is a general purpose AI and it is much more difficult to write than a battle specific AI. One of the key aspects of the General Staff Wargaming System is that users can create new armies, maps and scenarios. MATE must make good decisions in unusual circumstances.
Previously, I have shown MATE’s analysis of 1st Bull Run and Antietam. Below is the battle of Little Bighorn in the General Staff AI Editor:
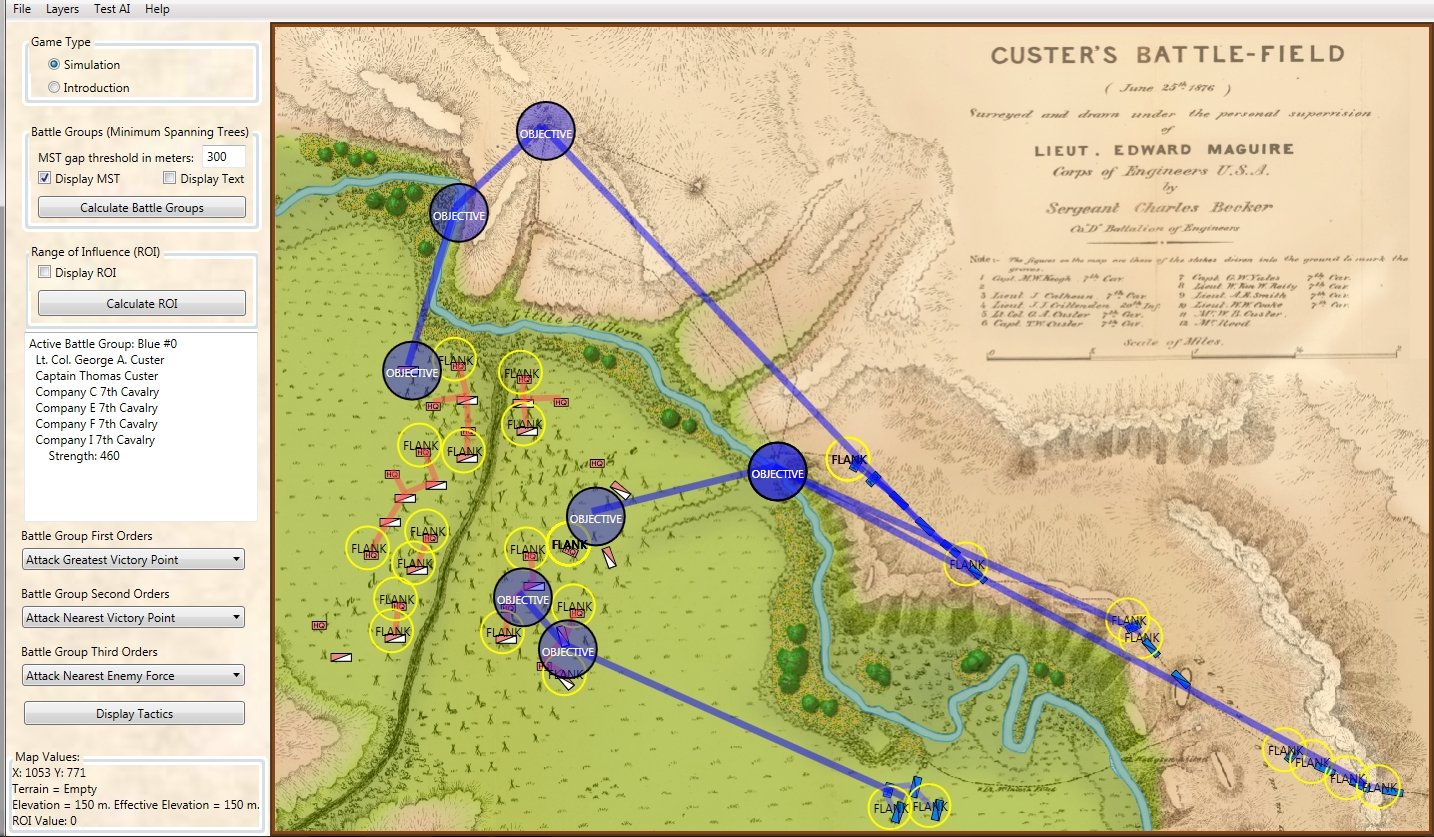
The battle of Little Bighorn in the General Staff AI Editor. Normally the MATE AI would decline to attack. However, when ordered to attack, this is MATE’s optimal plan. Click to enlarge.
I would like to expose MATE to at least thirty different tactical situations before releasing the General Staff Wargame. This is a slow process. Thanks to Glenn Frank Drover of Forbidden Games, Inc. for donating the superb Quatre Bras map. He also gave us maps for Ligny and Waterloo which will be the next two scenarios submitted to MATE. We still have a way to go to get up to thirty. If anybody is interested in helping to create more scenarios please contact me directly.
References
| ↑1 | It was first described in Turing’s, “On Computing Machines with an Application to the Entscheidungsproblem,” in 1937 which can be downloaded here: https://www.cs.virginia.edu/~robins/Turing_Paper_1936.pdf. Also a very good book on the subject is Charles Petzold’s, “The Annotated Turing: A Guided Tour through Alan Turing’s Historic Paper on Computability and the Turing Machine.” |
|---|---|
| ↑2 | Yes, somebody has built one and you can see what Turing described here: https://www.youtube.com/watch?v=E3keLeMwfHY |
| ↑3 | Thank you Dennis Beranek for introducing me to the concept of ‘reasonableness test’. See https://www.general-staff.com/schwerpunkt/ for explanation |
| ↑4 | Part of the problem with Netflix’s system is that they hire out of work scriptwriters to tag each movie with a number of descriptive phrases. Correctly categorizing movies is more complex than this. |