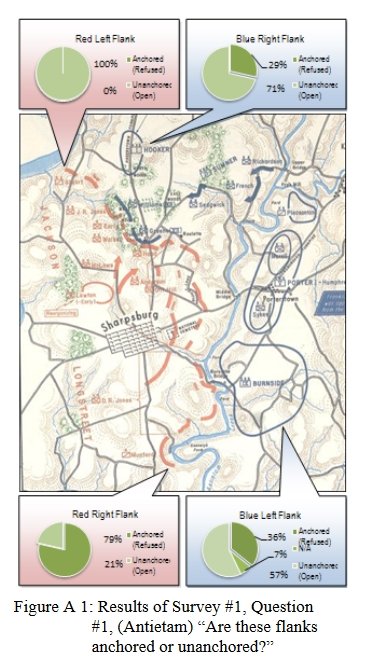
In my previous three posts on computational military reasoning (tactical artificial intelligence) we introduced my algorithms for detecting the absence or presence of anchored and unanchored flanks, interior lines and restricted avenues of attack (approach) and retreat. In this post I present my doctoral research1)TIGER: An Unsupervised Machine Learning Tactical Inference Generator which can be downloaded here which utilizes these algorithms, and others, in the construction of an unsupervised machine learning program that is able to classify the current tactical situation (battlefield) in the context of previously observed battles. In other words, it learns and it remembers.

‘Machine learning’ is the computer science term for learning software (in computer science ‘machine’ often means ‘software’ or ‘program’ ever since the ‘Turning Machine'2)https://en.wikipedia.org/wiki/Turing_machine which was not a physical machine but an abstract thought experiment.
There are two forms of machine learning: supervised and unsupervised machine learning. Supervised machine learning requires a human to ‘teach’ the software. An example of supervised machine learning is the Netflix recommendation system. Every time you watch a show on Netflix you are teaching their software what you like. Well, theoretically. Netflix recommendations are often laughingly terrible (no, I do not want to see the new Bratz kids movie regardless of how many times you keep recommending it to me).
Unsupervised machine learning is a completely different animal. Without human intervention an unsupervised machine learning program tries to make sense of a series of ‘objects’ that are presented to it. For the TIGER / MATE program, these objects are battles and the program classifies them into similar clusters. In other words, every time TIGER / MATE ‘sees’ a new tactical situation it asks itself if this is something similar (and how similar) to what it’s seen before or is it something entirely new?
I use convenient terms like ‘a computer tries to make sense of’ or a ‘computer sees’ or a ‘computer thinks’ but I’m not trying to make the argument that computers are sentient or that they see or think. These are just linguistic crutches that I employ to make it easier to write about these topics.
So, a snapshot of a battle (the terrain, elevation and unit positions at a specific time) is an ‘object’ and this object is described by a number of ‘attributes’. In the case of TIGER / MATE, the attributes that describe a battle object are:
- Interior Line Value
- Anchored / Unanchored Flank Value
- REDFOR (Red Forces) Choke Points Value
- BLUEFOR (Blue Forces) Choke Points Value
- Weighted Force Ratio
- Attack Slope
The algorithms for calculating the metrics for the first four attributes were discussed in the three previous blog posts cited above. The algorithms for calculating the Weighted Force Ratio and Attack Slope metrics are straightforward: Weighted Force Ratio is the strength of Red over the strength of Blue weighted by unit type and the Attack Slope is just that: the slope (uphill or downhill) that the attacker is charging over.
TIGER / MATE constructs a hierarchical tree of battlefield snapshots. This tree represents the relationship and similarity of different battlefield snapshots. For example, two battlefield situations that are very similar will appear in the same node, while two battlefield situations that are very different will appear in disparate nodes. This will be easier to follow with a number of screen shots. Unfortunately, we first have to introduce the Category Utility Function.
So, first let me apologize for all the math. It isn’t necessary for you to understand how the TIGER / MATE unsupervised machine learning process works, but if I don’t show it I’m guilty of this:


The Category Utility Function (or CU, for short) is the equation that determines how similar or dissimilar too objects (battlefields) are. This it the CU function:

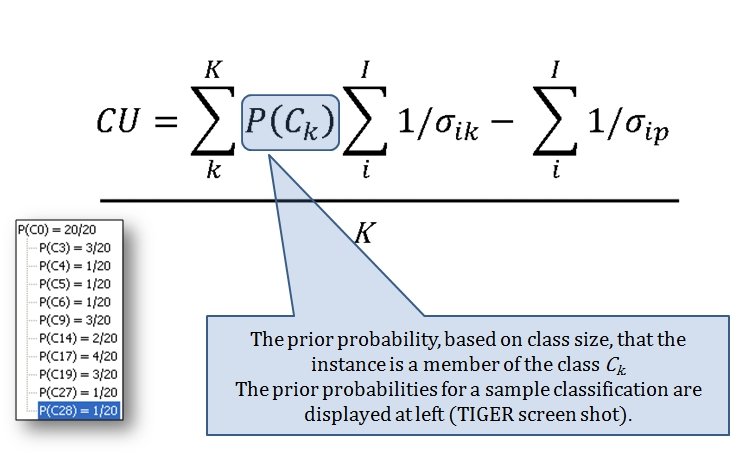
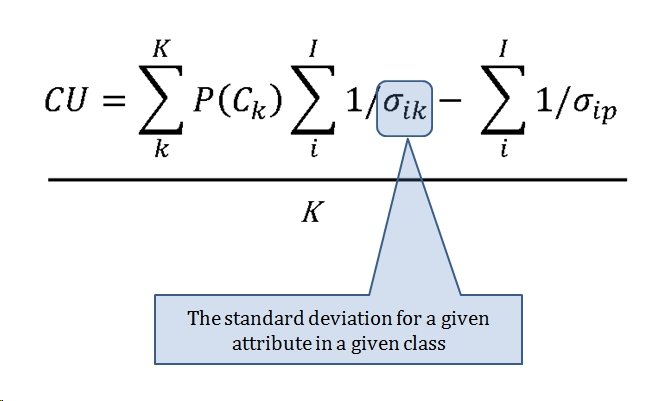
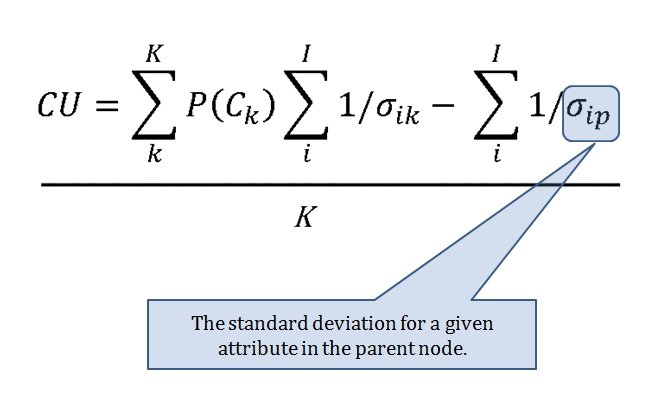
‘Acuity’ is the concept of the minimum value that separates two ‘instances’ (in our case, battles). It has to have a value of 1.0 or very bad things will happen.


So, let’s recap what we’ve got:
- A series of algorithms that analyze a battlefield and return values representing various conditions that SMEs agree are significant (flanks, attack and retreat routes, unit strengths, etc., etc).
- A Category Utility Function (CU) that uses the products of these algorithms to determine how similar analyzed battlefields are.
So now, we just need to put this all together. A battlefield (tactical situation) is analyzed by TIGER / MATE. It is ‘fed’ into the unsupervised machine learning function and, using the Category Utility Function one of four things happen:
- All the children of the parent node are evaluated using the CU function and the object (tactical situation)is added to an existing node with the best score.
- The object is placed in a new node all by itself.
- The two top-scoring nodes are combined into a single node and the new object is added to it.
- A node is divided into several nodes with the new objected to one of them.
These rules (above) construct a hierarchical tree structure. TIGER was fed 20 historical tactical situations (below):
- Kasserine Pass February 14,1943
- KasserinePass February 19, 1943
- Lake Trasimene, 217 BCE
- Shiloh Day 2
- Shiloh Day 1, 0900 hours
- Shiloh Day 1, 1200 hours
- Antietam 0600 hours
- Antietam 1630 hours
- Fredericksburg, December 10
- Fredericksburg, December 13
- Chancellorsville May 1
- Chancellorsville May 2
- Gazala
- Gettysburg, Day 1
- Gettysburg, Day 2
- Gettysburg, Day 3
- Sinai, June 5
- Waterloo, 1000 hours
- Waterloo, 1600 hours
- Waterloo, 1930 hours
In addition to these 20 historical tactical situations five hypothetical situations were created labeled A-E. This is the resulting tree which TIGER created:
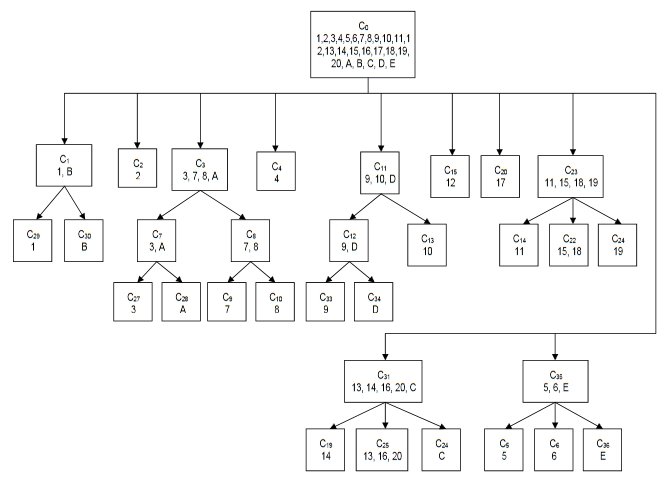
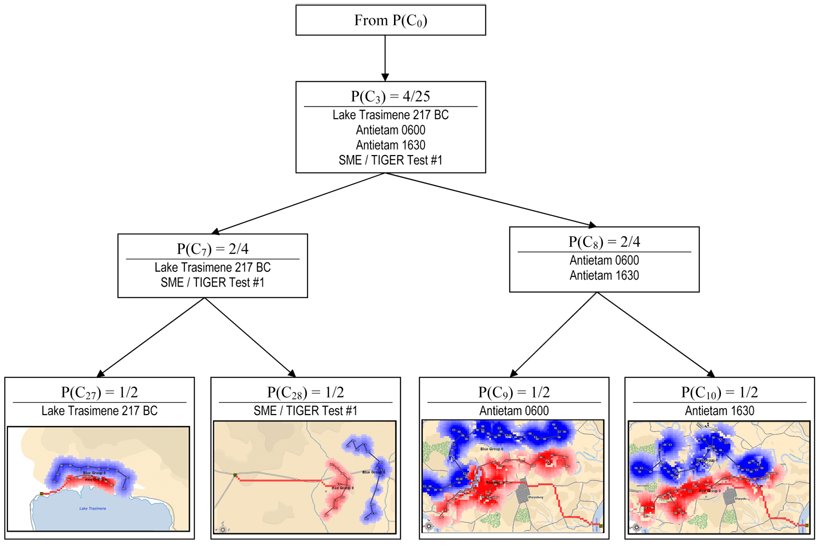
The hierarchical tree created by TIGER from 20 historical and 5 hypothetical tactical situations. The numbers in the nodes refer to the above legend. Battles placed in the same nodes are considered very similar by TIGER. Click to enlarge.
If we look at the tree that TIGER constructed we can see that it placed Shiloh Day 1 0900 hours and Shiloh Day 1 1200 hours together in cluster C35. Indeed, as we look around the tree we observe that TIGER did a remarkable job of analyzing tactical situations and placing like with like. But, that’s easy for me to say, I wrote TIGER. My opinion doesn’t count. So we asked 23 SMEs which included:
- 7 Professional Wargame Designers
- 14 Active duty and retired U. S. Army officers including:
- Colonel (Ret.) USMC infantry 5 combat tours, 3 advisory tours
- Maj. USA. (SE Core) Project Leader, TCM-Virtual Training
- Officer at TRADOC (U. S. Army Training and Doctrine Command)
- West Point; Warfighting Simulation Center
- Instructor, Dept of Tactics Command & General Staff College
- PhD student at RMIT
- Tactics Instructor at Kingston (Canada)
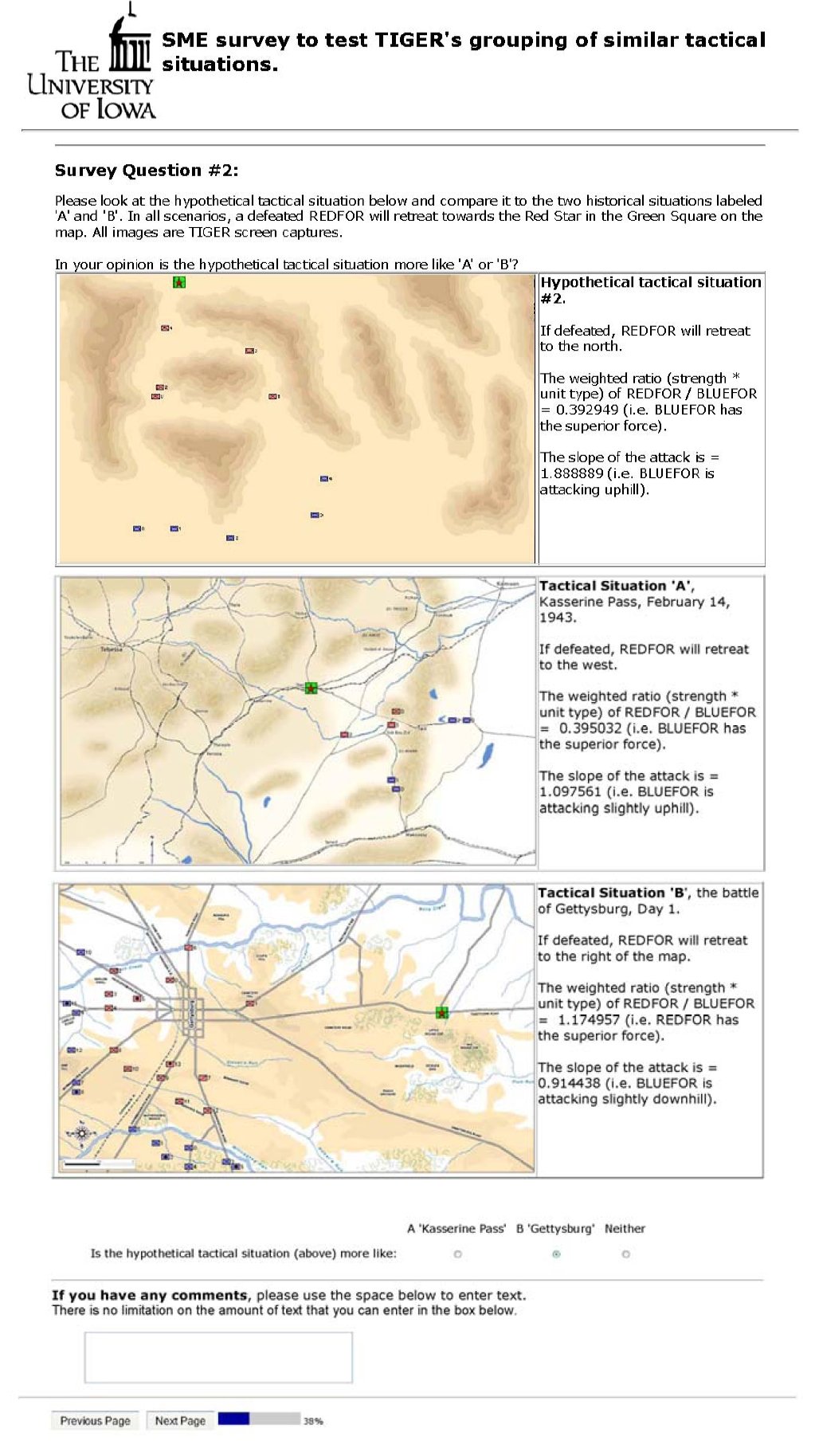
And in a blind survey asked them not what TIGER did but what they would do. For example:
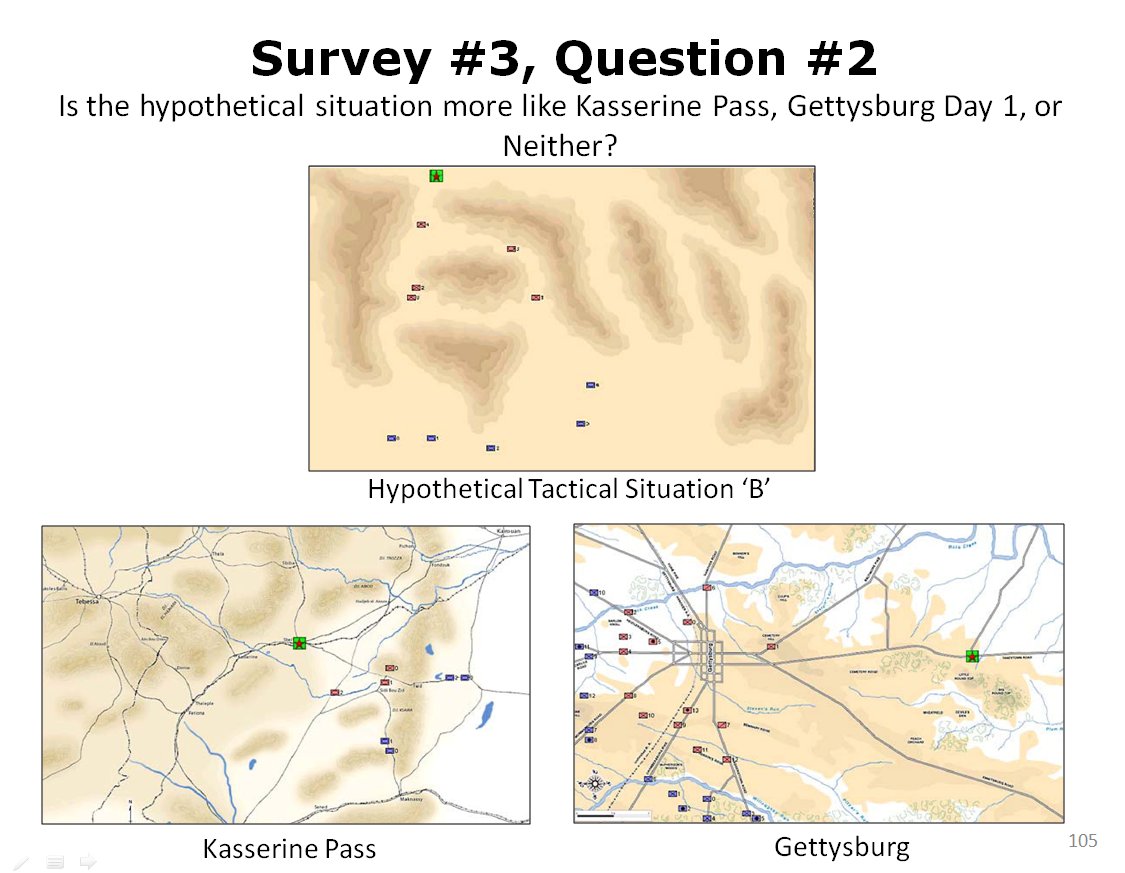
Twenty-three SMEs were asked this question: is this hypothetical tactical situation (top) more like Kasserine Pass or Gettysburg?. Click to enlarge.
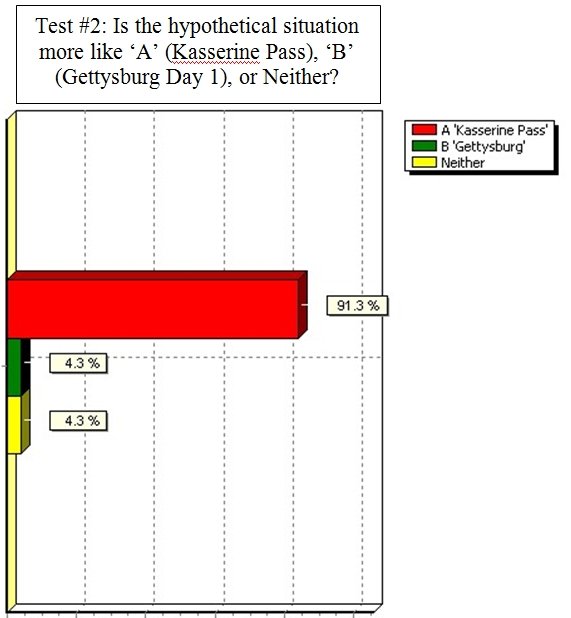
And this is how the responded:
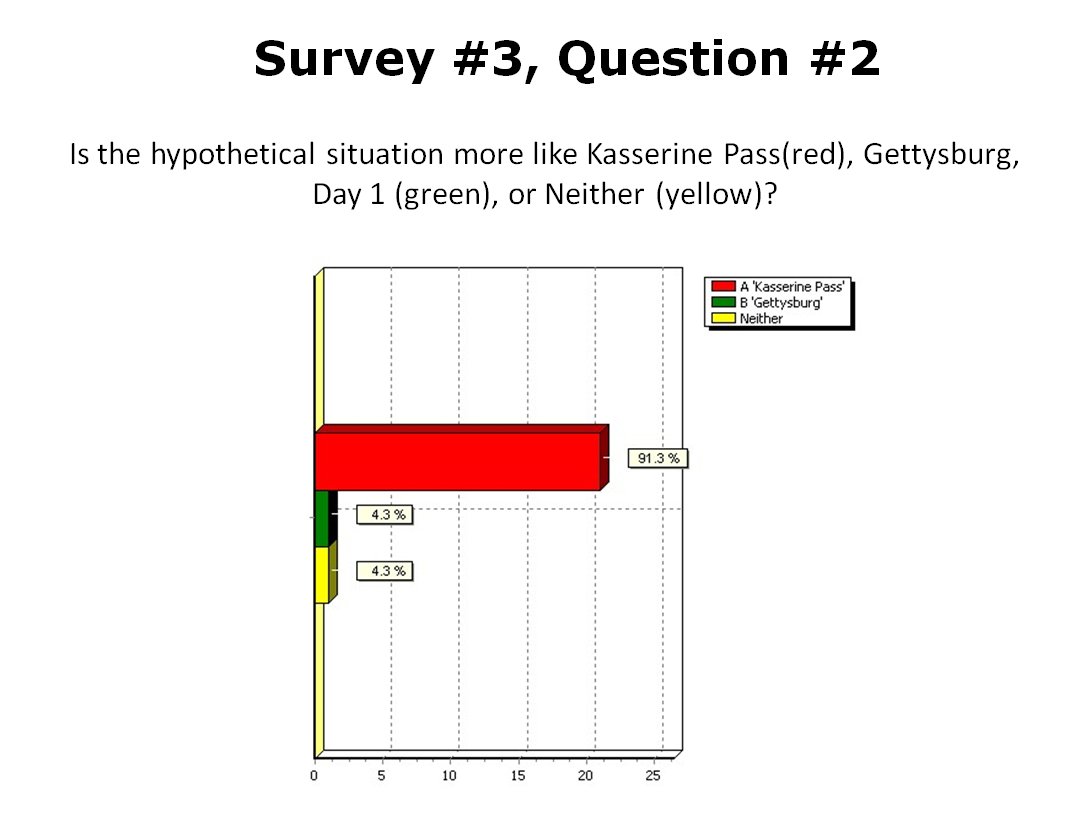
Results from 23 SMEs answering the above question. Overwhelmingly the SMEs agreed that that the hypothetical tactical situation was most like the battle of Kasserine Pass.
So, 91.3% of SMEs agreed that the hypothetical tactical situation was more like Kasserine Pass than Gettysburg Day 1. Unbeknownst to the SMEs TIGER had already classified these three tactical situations like this:
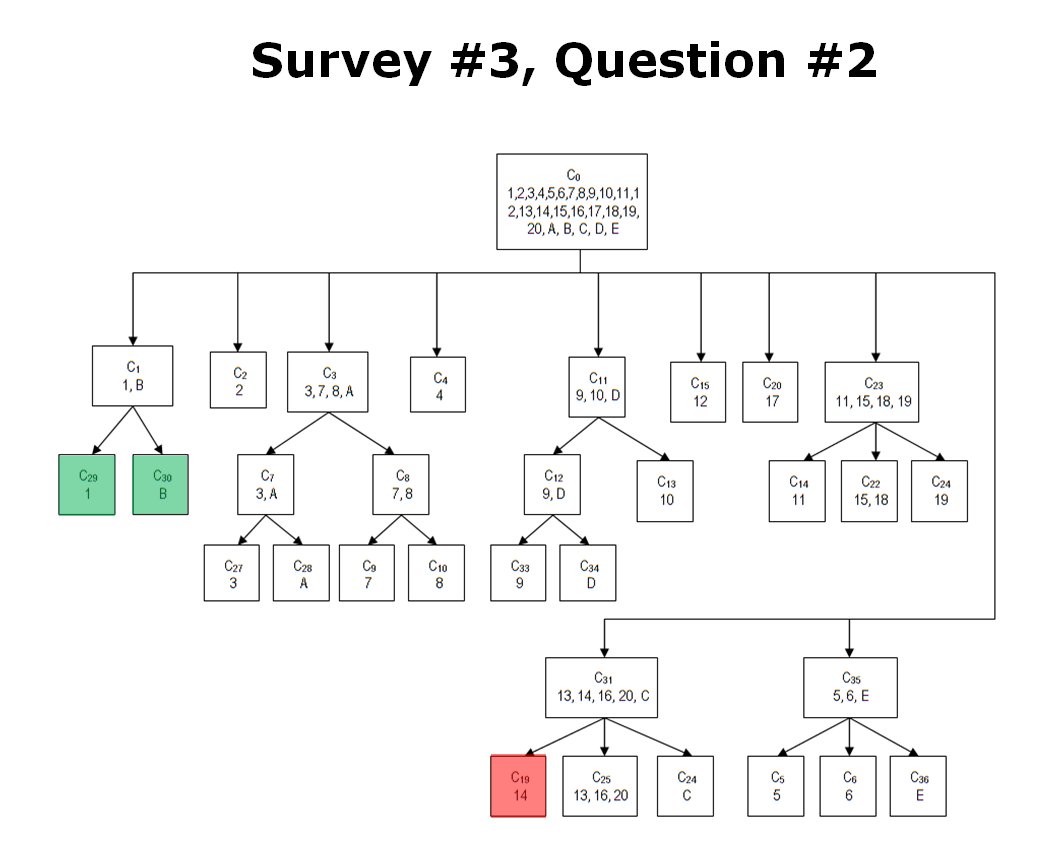
How TIGER classified Kasserine Pass (1), Gettysburg Day 1 (14) and a hypothetical tactical situation (B). The cluster C1 contains two tactical situations that both have restricted avenues of attack caused by armor traveling through narrow mountainous passes. These passes also partially create restricted avenues of retreat. REDFOR does not have anchored flanks.Click to enlarge.
In conclusion: over the last four blog posts about Computational Military Reasoning we have demonstrated:
- Algorithms for analyzing a battlefield (tactical situation).
- Algorithms for implementing offensive maneuvers.
- An Unsupervised Machine Learning system for classifying tactical situations and clustering like situations together. Furthermore, this system is never-ending and as it encounters new tactical situations it will continue this process which enables the AI to plan maneuvers based on previously observed and annotated situations.
This is the AI that will be used in General Staff. It is unique and revolutionary. No computer military simulation – either commercially available or any military simulation used by any of the world’s armies – employ an AI of this depth.
As always, please feel free to contact me directly with questions or comments. You can use our online email form here or write to me directly at Ezra [at] RiverviewAI.com.
References
| ↑1 | TIGER: An Unsupervised Machine Learning Tactical Inference Generator which can be downloaded here |
|---|---|
| ↑2 | https://en.wikipedia.org/wiki/Turing_machine |