Click on the above to launch a YouTube video about General Staff gameplay & AI.
This feels like a propitious moment; at least I’m drinking some decent scotch. I’ve got the AI that I’ve written ad nauseum about (links: papers, thesis) hooked up to the General Staff engine. This was something that, on paper, was supposed to be pretty easy but in the real world took far too long.
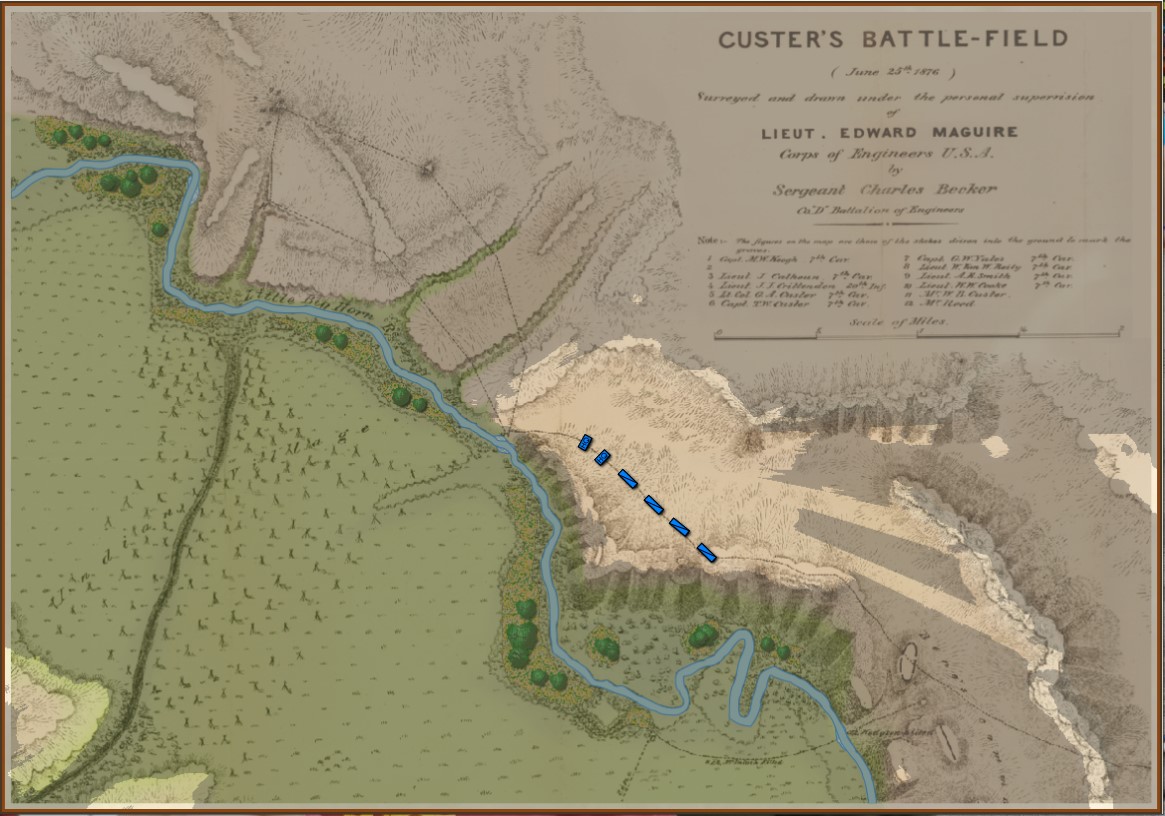
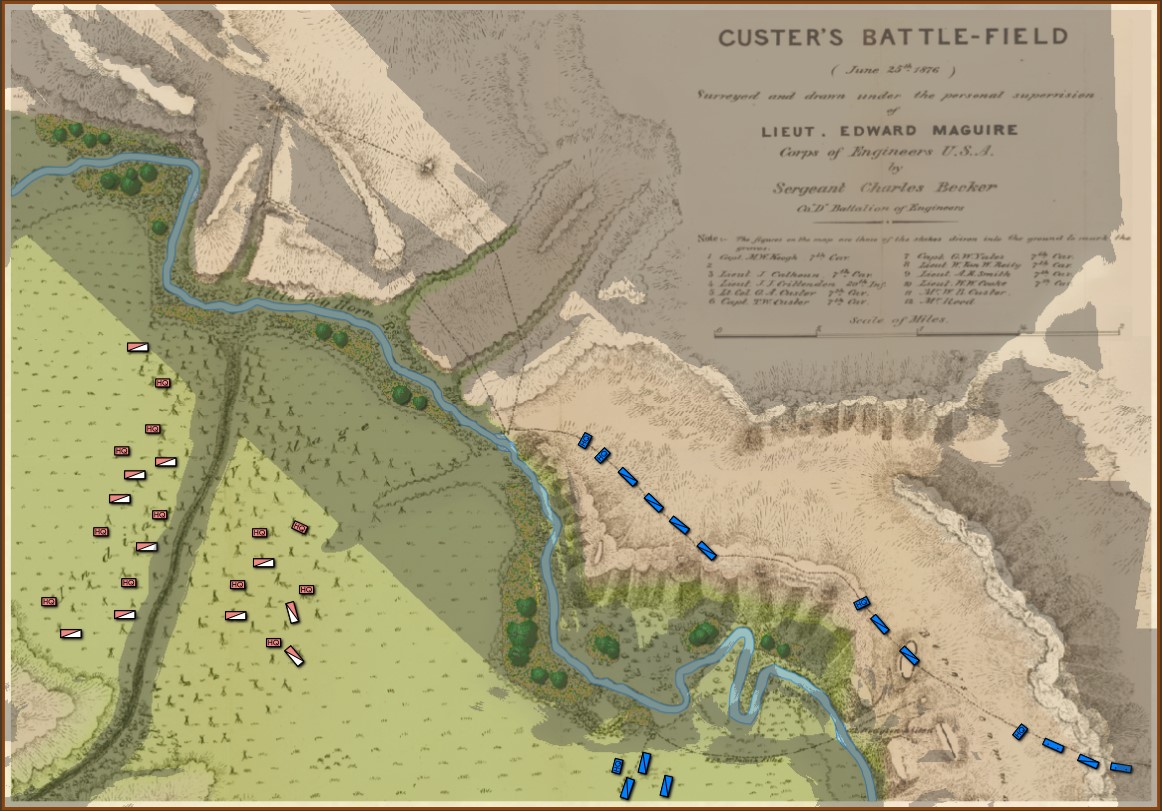
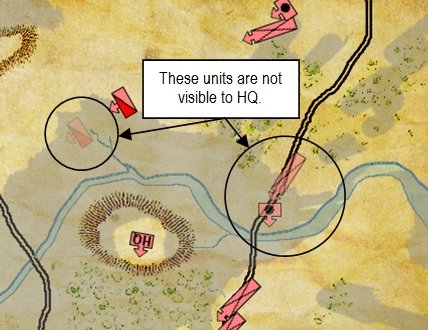
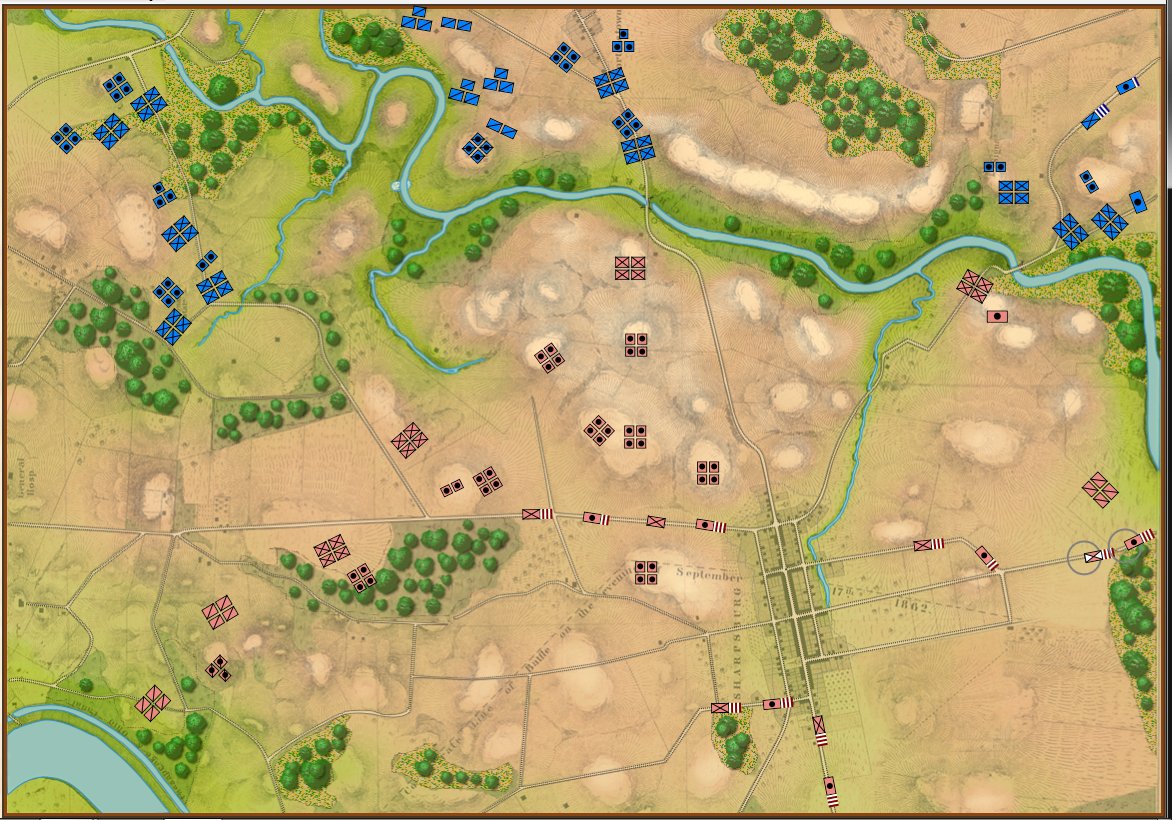
So, the short read is that if you want to take a look at what the General Staff AI engine looks like, please watch the video. It is mostly an offensive monster. It knows how to attack. It looks for open flanks. Then it looks for weak points on the line. Defense is difficult and there is still more work to do.
Also, we need more user created scenarios to test the AI on.
N.B. We don’t need more scenarios to train the AI. That’s not how MATE (Machine Analysis of Tactical Environments) works. It is a case-based reasoning AI. It is not a Large Language Model (LLM). It is not Grok, or ChatGPT, or Claude. Because it reasons. It – for lack of a better word – understands things. It understands what a flank is and it tries to turn it with its units. LLMs string words together that they’ve scraped from wherever and hope that you like them (they have a sycophancy reinforcement loop to optimize user engagement).
Someone fed one of my papers about TIGER (Tactical Inference Generator) into an LLM and asked it if it could perform this kind of reasoning. This was the reply:
Your skepticism is well-founded, and the paper you cite makes the reason precise rather than rhetorical.
The notion of an open or refused flank, as formalized in TIGER, is not a linguistic classification problem but a geometric and topological predicate over a continuous battlespace with adversarial constraints. In your formulation, a flank is anchored if and only if no BLUEFOR unit admits a legal path to a flanking objective that avoids REDFOR range-of-influence regions, where legality is defined with respect to terrain, slope, line of sight, and unit-specific mobility costs. That definition reduces to constrained path existence in a weighted graph whose edge weights and forbidden regions are dynamically induced by force disposition and terrain, not by labels or prior text. The algorithm explicitly constructs MST spines, computes continuous ROIs, projects objective points, and then solves repeated adversarial path-planning problems via A* or equivalent search. This is fundamentally an algorithmic decision procedure, not a pattern-completion task.
An LLM, by itself, cannot calculate this in any meaningful sense. It has no internal representation of continuous space, no native notion of reachability under constraints, no ability to execute minimum spanning tree construction, and no mechanism for guaranteeing correctness of a path-existence claim. At best, it can paraphrase the doctrine or restate the algorithm. It cannot answer the question “is the left flank refused?” without the explicit computational machinery you describe, because the answer is not a heuristic judgment but the outcome of a well-defined search problem.
Where the distinction becomes important is separating computation from orchestration. An LLM cannot replace the TIGER flanking algorithm any more than it can replace Dijkstra’s algorithm. However, it can sit above such machinery. Given access to the state representation and the outputs of ComputeGroupsByThreshold, CalculateROI, and FindPath, an LLM could reason symbolically about the results, explain why a flank is anchored, compare cases across battles, or assist a human analyst in interpreting why a particular BLUEFOR unit was forced through an ROI. In that role it is a narrative or analytic layer, not the reasoning engine itself.
Your broader point about Computational Military Reasoning stands: this class of military concepts only becomes machine-tractable when doctrine is grounded in geometry, graph theory, and constrained optimization. Anchored flanks, interior lines, and restricted avenues of approach are computable precisely because you reduced them to measurable invariants over space and movement. That reduction is what makes them suitable for case-based reasoning and unsupervised classification in systems like ClassIT, and it is exactly what an LLM does not do.
So the short answer is no: an LLM cannot calculate whether a flank is open or refused. The longer and more interesting answer is that your work shows why that question has a correct answer at all, and why tactical reasoning belongs to algorithms first and language models, if anywhere, only downstream of them.
I would just like to say that this LLM (above) wrote a superb analysis of my life’s work in computer science. Furthermore, it separated my work in cased base reasoning from its own LLM existence: It [an LLM] cannot answer the question “is the left flank refused?” without the explicit computational machinery you describe, because the answer is not a heuristic judgment but the outcome of a well-defined search problem.
I understand that there are fortunes, tenures, endowments, and founder’s stock to be won now in the race to LLMs, but I assure you, it is a parlor trick, it is simple word manipulation; it is a conjurer’s legerdemain.
To me the bon mot is, “An LLM cannot replace the TIGER flanking algorithm any more than it can replace Dijkstra’s algorithm.”
Dijkstra’s algorithm. I did my Q exam, my Qualifying Exam on Least Weighted Path algorithms. The Q exam comes around Year Three; it is where you have to demonstrate the ability to perform real research at a Research One University. Dijkstra’s algorithm is an exhaustive search and A* is a heuristic search. Dijkstra’s algorithm is guaranteed to find the optimal path, but it takes forever (O((V + E) log V)). While A* runs in ( ). If by some amazing luck of the draw you also have to defend this in your Q Exam, you just got all the answers you need to remember to move on to Round Four: your Comprehensive Exam (AKA, “The Comps”).

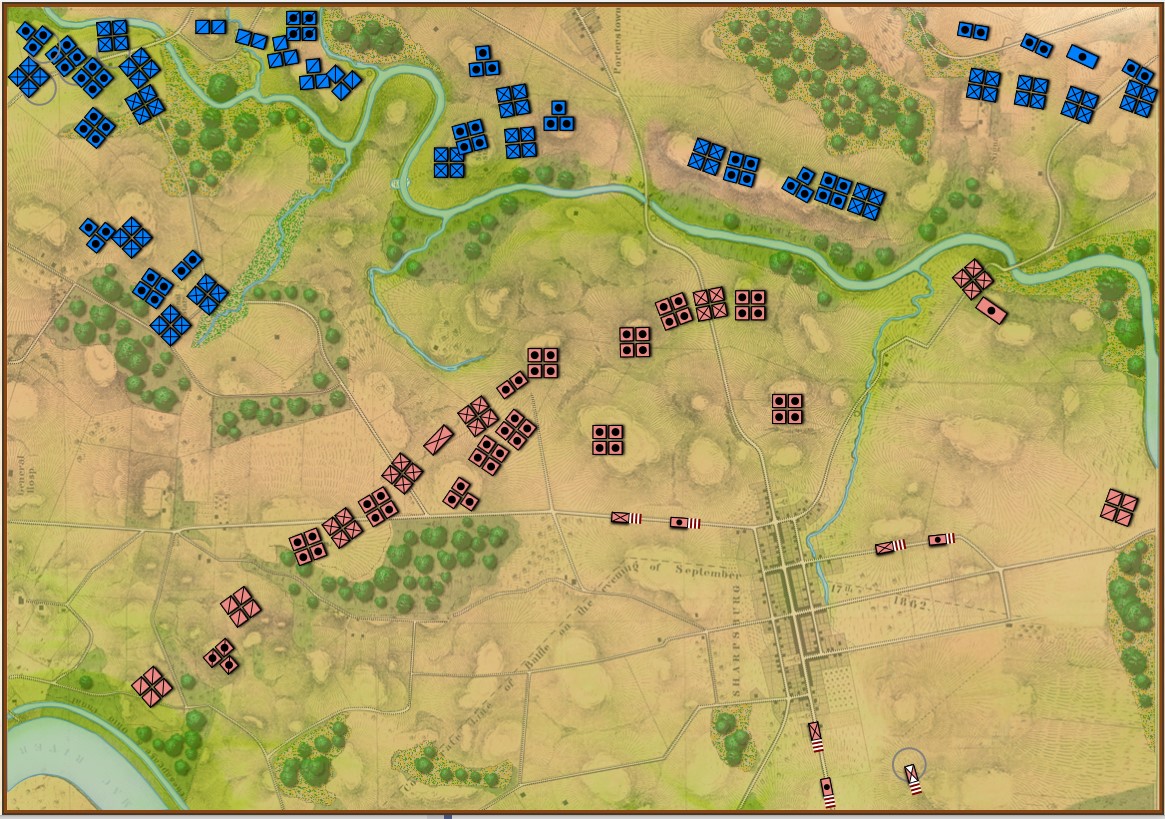
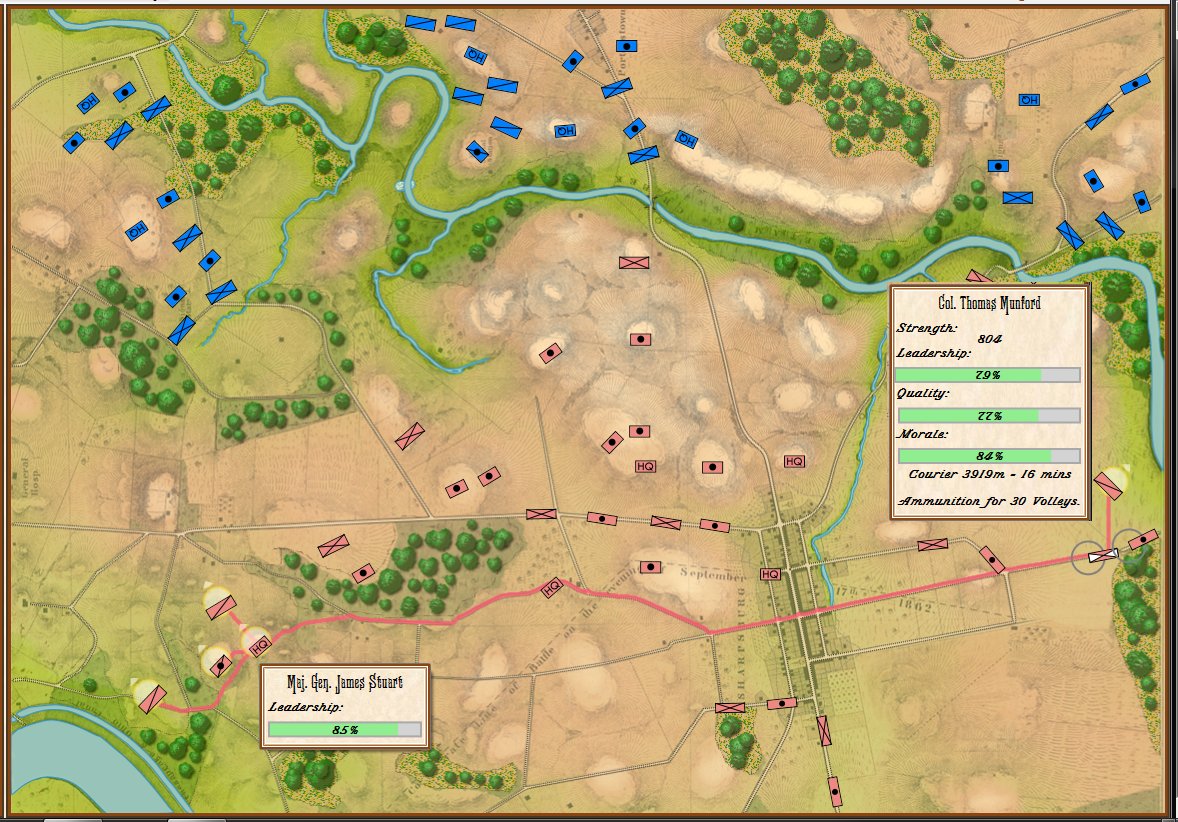
But, I digress. I confess that this was the first time I witnessed the AI act like this. Frankly, I was impressed when the AI unleashed the BLUE cavalry at the decisive moment towards the schwerpunkt. It was calculated using Kruskal’s Minimum Spanning Tree algorithm.
What I’m trying to say, and I have trouble explaining this without anthropomorphizing, but the MATE algorithms look at a snapshot of a battlefield, analyze it, perform numerous geometric calculations – especially those involving 3D line of sight (3D LOS), range of influence (ROI), locating flanking units, interior lines of communications, projections of force, etc. – and it comes up with a Course of Action (COA) that is, at least in the above video, better than what Major General did at Antietam (in all candor, this is a pretty low bar). For starters, the AI is very aggressive and it hammered hard upon all three routes into Sharpsburg. Eventually RED’s left flank crumbled and the AI (BLUE) won.
Yeah, I’m proud of the AI. But, I need more scenarios to test the AI against. That’s where you come in. All the information is in the above video.
,