
It’s easy to say that you want to create an artificial intelligence that is capable of making human-level tactical decisions but that’s just not how it’s done in academia. First off, the term ‘human-level’ is vague. And then there’s the question of how do you prove your claim? I am indebted to Professor (now Dean) Joe Kearney who proposed the following hypotheses to state my doctoral thesis:
Hypothesis 1: There is agreement among military experts that tactical situations exhibit certain features (or attributes) and that these features can be used by SMEs (Subject Matter Experts) to group tactical situations by similarity.
Hypothesis 2: The best match by TIGER (the Tactical Inference Generator program) of a new scenario to a scenario from its historical database predicts what the experts would choose.
In other words, a preponderance of SMEs will describe a tactical situation in the same way (like ‘Blue has a severely restricted line of retreat’ or ‘Red has anchored flanks’) and a computer program can be written that will describe the same battlefield in the same way as the human experts. And, if TIGER correctly predicts what the SMEs would choose in four out of five tests (using a one sided Wald test resulted in p = 0.0001 which is statistically significant) you get a PhD in Computer Science. By the way, I am also indebted to Dr. Joseph Lang of the Department of Statistics and Actuarial Science at the University of Iowa who calculated the p value.
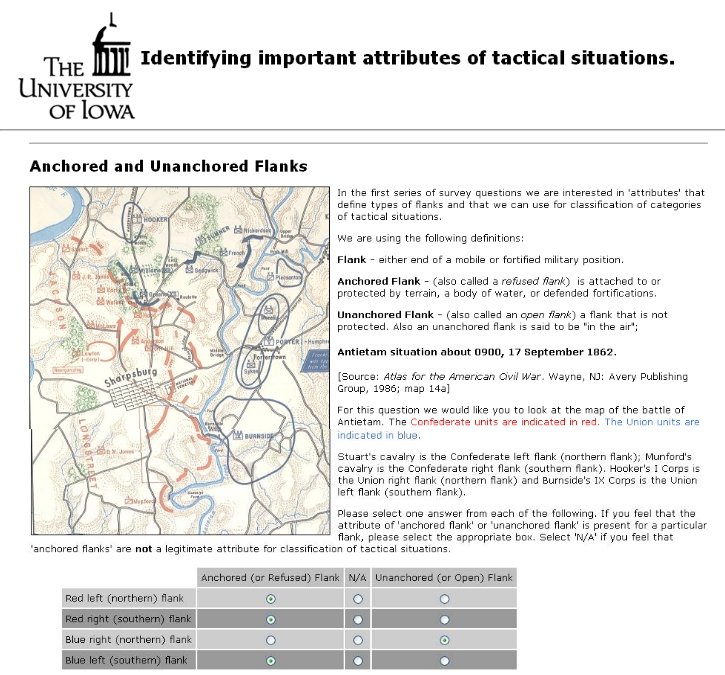
An example of an online survey tactical description question asked of Subject Matter Experts. Image from Sidran’s TIGER: A Tactical Inference Generator. Click to enlarge.
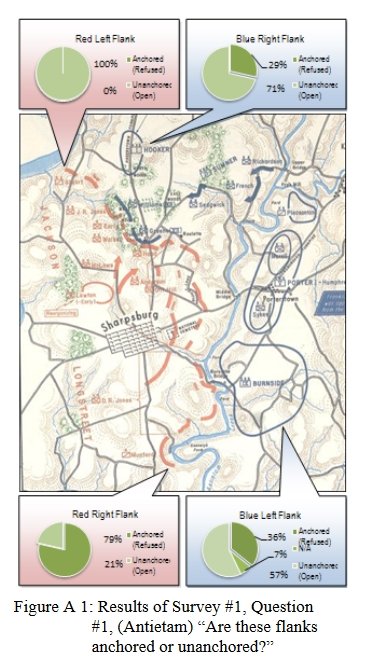
The results of the above survey question: 100% of SMEs agree that RED’s left flank is anchored on the Potomac; 79% agree that RED’s right flank is anchored on the Antietam. Image from Sidran’s TIGER: A Tactical Inference Generator. Click to enlarge.
The descriptors (features or attributes) that were identified by the SMEs included Anchored Flanks, Unanchored Flanks, Restricted Avenues of Attack, Unrestricted Avenues of Attack, Restricted Avenues of Retreat, Unrestricted Avenues of Retreat and Interior Lines. If you are interested in the methodology and algorithms there are links at the end of this post.
Now that the features have been identified (and algorithms written and tested that return a value representing the extent of the attribute) the next step is separating battlefield situations into categories is creating a machine learning classifier program.
There are two kinds of machine learning programs: supervised and unsupervised. Imagine two kinds of fish coming down a conveyor belt with a human being watching this on a TV with two buttons to push. If he pushes the button on the left the fish is classified as, say, ‘tuna’. And if he pushes the button the right the fish is classified as a ‘catfish’. (Why tuna and catfish are coming down this conveyor belt is beyond me, but please stay with the explanation.). In this way the program is taught the difference between a tuna and a catfish (tuna are bigger and longer). This is called supervised learning and is the method used by Netflix and Spotify to select movies or songs that are similar to choices you have previously made. I don’t like supervised systems because they have to be ‘trained’ and, in my opinion, have a tendency to oversimplify classification problems (for example, Netflix movie suggestions are usually awful).
Unsupervised machine learning works differently: there are a number of ‘objects’ that are described with certain ‘attributes’. These objects are presented to the ‘machine’ and the machine separates them into categories based on the likelihood (probability) that they belong together and then displays the results in a hierarchical tree structure. This is how the TIGER program works. The ‘objects’ are battlefield maps and the attributes are things like ‘anchored flanks’ and ‘restricted lines of attack’.
In the image, below, one branch of a tree structure of classified battles (both real and hypothetical) is displayed:
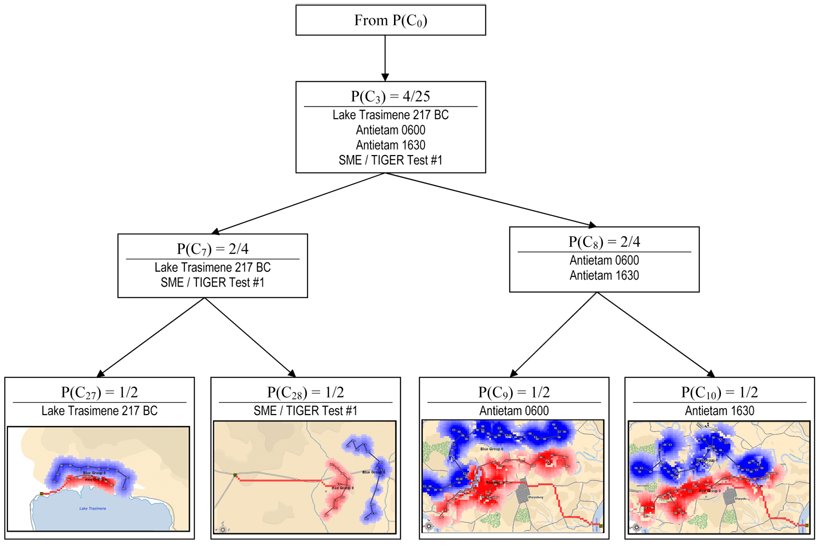
TIGER has classified four battlefield snapshots (Lake Trasimene 217 BC, Antietam 0600 hours, Antietam 1630 hours and a test battlefield submitted to TIGER and the SMEs as being similar. Note how TIGER sees the two Antietam snapshots as ‘more similar’ and puts them in their own node. Image taken from TIGER: An Unsupervised Machine Learning Tactical Inference Generator. Click to enlarge.
The method that TIGER uses to classify battlefields is Gennari, Fisher and Langley’s ClassIT algorithm which is explained in detail in my thesis (link below). Basically, a number of objects are ‘fed’ to the machine (in computer science the terms ‘machine’ and ‘program’ are synonymous) and every time the machine ‘consumes’ an object it asks itself, “does this new object belong in a previously existing category, or a new category, or should I combine two existing categories and add this new object or should I split an existing category and add this new object to one of them? Caveat: just as I explained in the previous blog, computers don’t actually ‘say’ or ‘ask itself’ but it’s easier to explain these processes using those terms. This is unsupervised because there is no human involvement or training. And there is no limit to the number of objects (battlefields) that can be shown to the program. TIGER is constantly learning.
Below is an example blind survey question given to >20 SMEs to validate TIGER’s ability to predict what the majority of SMEs would choose. My good friend, Ralph Sharp, who has worked on art for many of my games did the hypothetical battlefield maps.
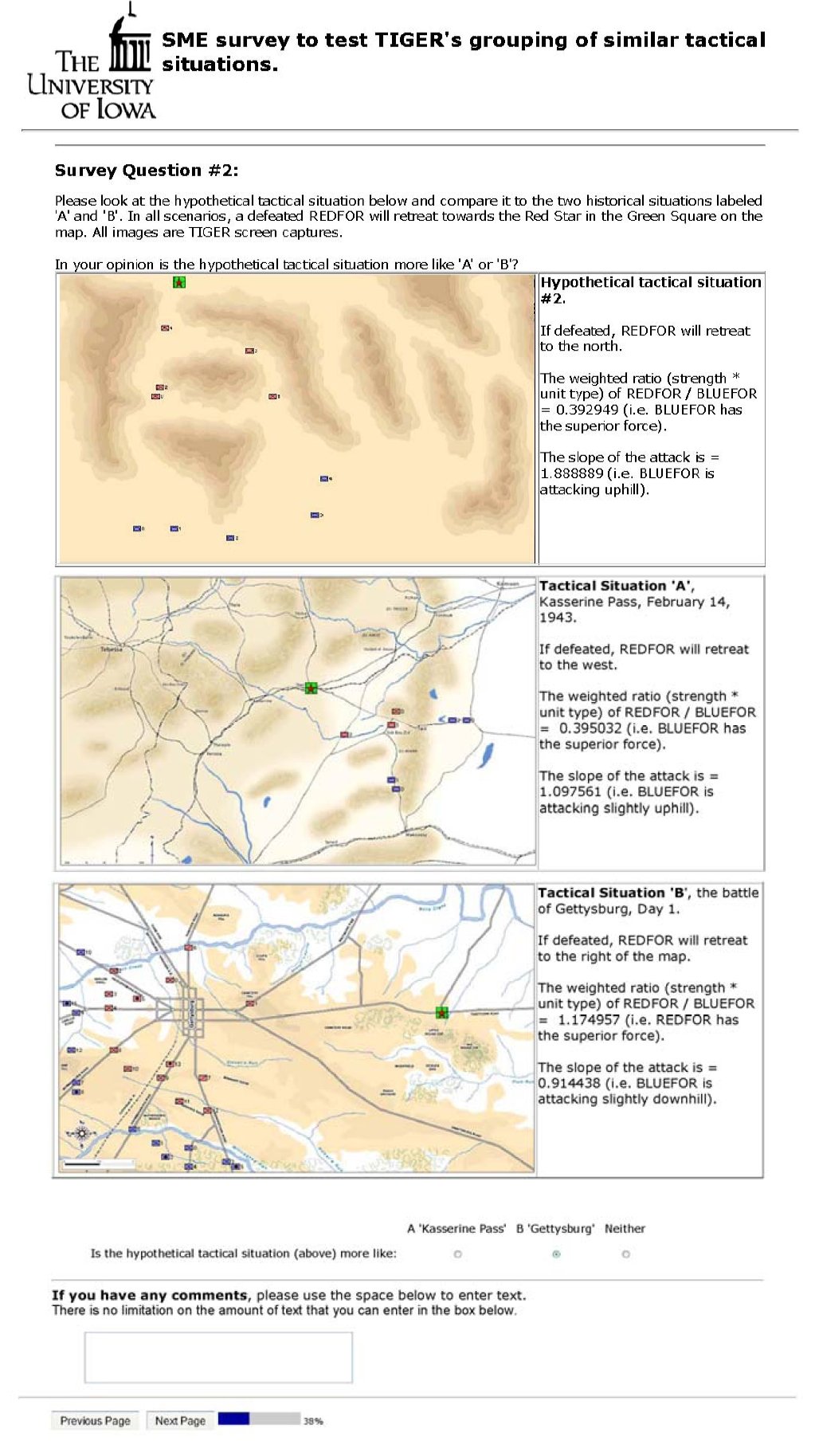
An example of the blind survey questions asked of SMEs: is the hypothetical battlefield situation on the top more like the historical battlefield in the middle (Kasserine Pass) or the historical battlefield at the bottom (Gettysburg). Click to enlarge.
The results show a statistically significant number of SMEs are in agreement that the hypothetical battlefield situation most closely resembles Kasserine Pass.
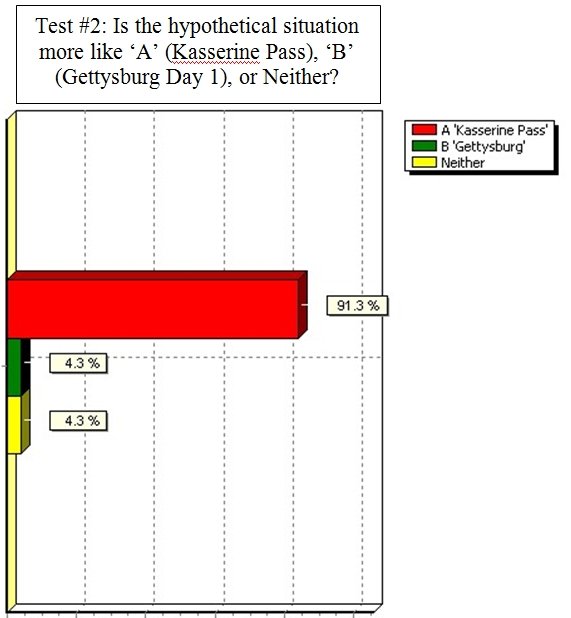
The results from the, above, blind survey question. The SMEs overwhelmingly state that the the battle of Kasserine Pass most resembles the hypothetical battle situation. The TIGER program also chose the ‘Kasserine Pass’. Click to enlarge.
Once again this week’s post ran longer than I anticipated. It looks like this story won’t conclude at least until Part 5. It has been said that by the time a PhD dissertation is defended only five people in the world are capable of understanding it. I certainly hope that wasn’t the case with my research. Below is a link to download a PDF of my thesis. Please feel free to contact me directly if I can answer any questions.
Lastly, my good friend Mike Morton, sent me a link to this piece just before my defense: The “Snake Fight” Portion of Your Thesis Defense. Anybody thinking of getting a PhD should probably read this first (and laugh and then cry).
Papers that were cited in this post with download links:
“Algorithms for Generating Attribute Values for the Classification of Tactical Situations.”
TIGER: An Unsupervised Machine Learning Tactical Inference Generator.
Thank you for such excellent reading material.
Pingback: A Wargame 55 Years in the Making (Part 5) | General Staff