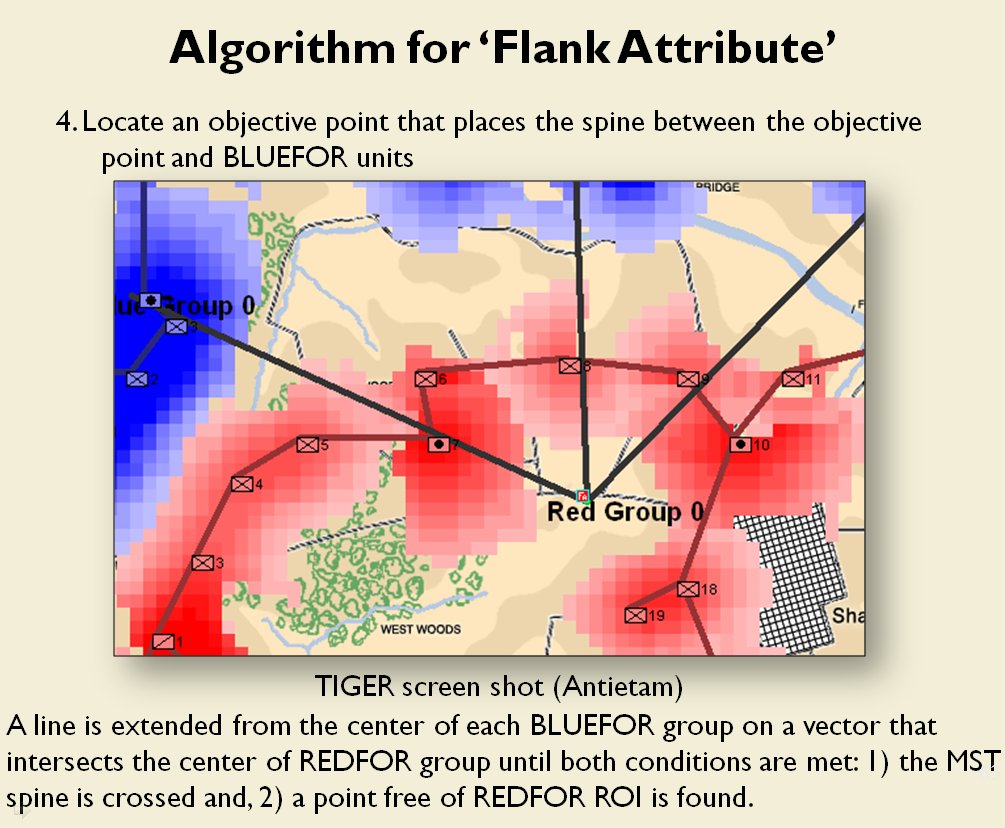
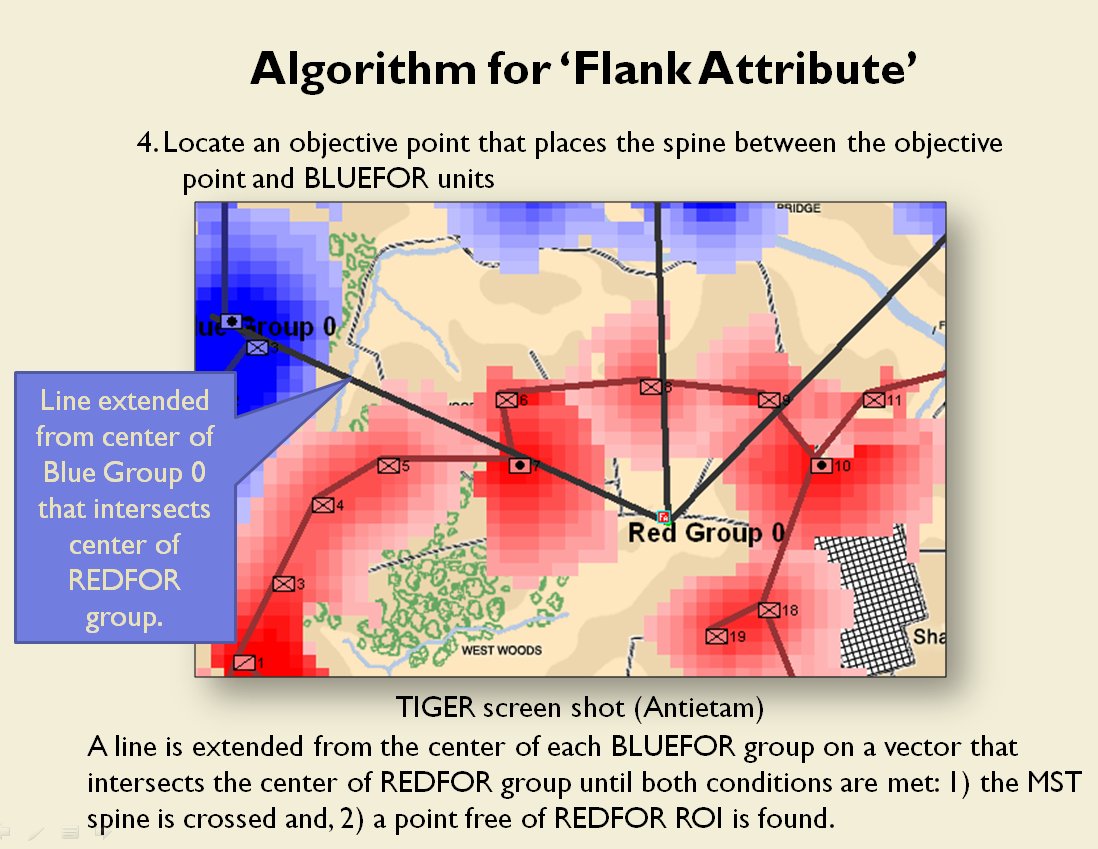
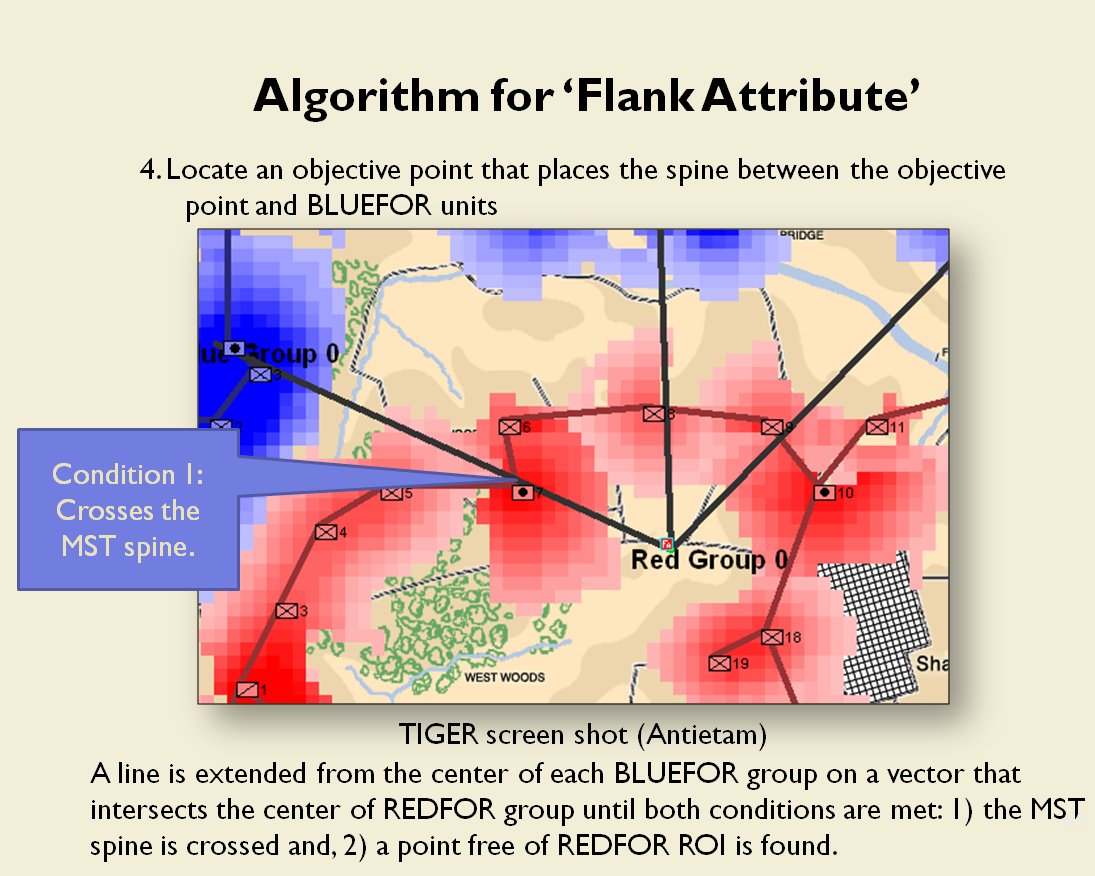
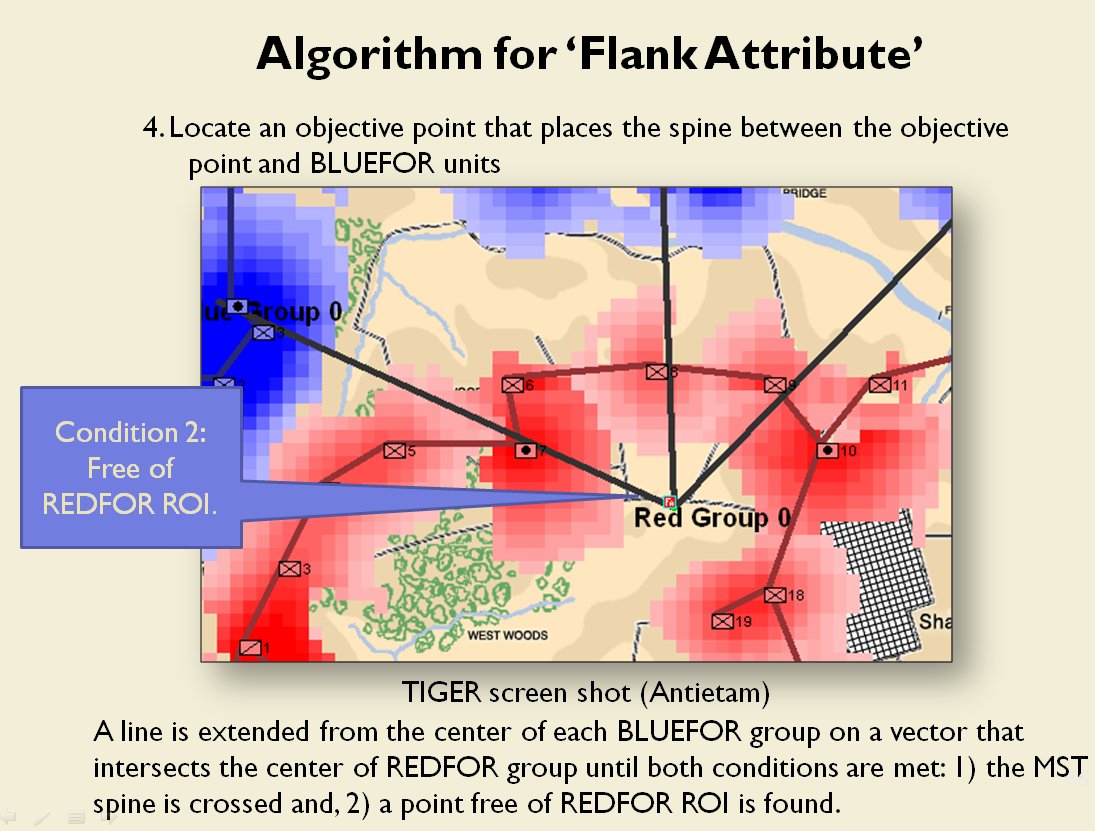
In two previous blogs I wrote about how Artificial Intelligence (AI) for wargames perceive battle lines and terrain and elevation. Today the topic is how computer AI has changed ‘Range of Influence’ (ROI) or ‘Zone of Control’ (ZOC) analysis. Range of Influence and Zone of Control are terms that can be used interchangeably. Basically, what they mean is, “how far can this unit project its power.”
One of the first appearances of range as a wargame variable was in Livermore’s 1882 American Kriegsspiel: A Game for Practicing the Art of War Upon a Topographical Map (superb article on American Kriegsspiel here). Note that incorporated into the ‘range ruler’ (below) is also a linear ‘effectiveness scale’.

Detail of Plate IV, “The Firing Board,” from the American Kriegsspil showing a ruler for artillery range printed on the top. Note the accuracy declines (apparently linearly) proportional to the distance. Click to enlarge.
The introduction of hexagon wargames (first at RAND and then later by Roberts at Avalon Hill; see here) created the now familiar 6 hexagon ‘ring’ for a Zone of Control:

Zone of Control explained in the Avalon Hill Waterloo (1962) manual. Author’s Collection.
I seem to remember an Avalon Hill game where artillery had a 2 hex range; but I may well be mistaken.
Ever since the first computer wargames that I wrote back in the ’80s I have earnestly tried to make the simulations as accurate as possible by including every reasonable variable. With the General Staff Wargaming System we’ve added two new variables to ROI: 3D Line of Sight and an Accuracy curve.
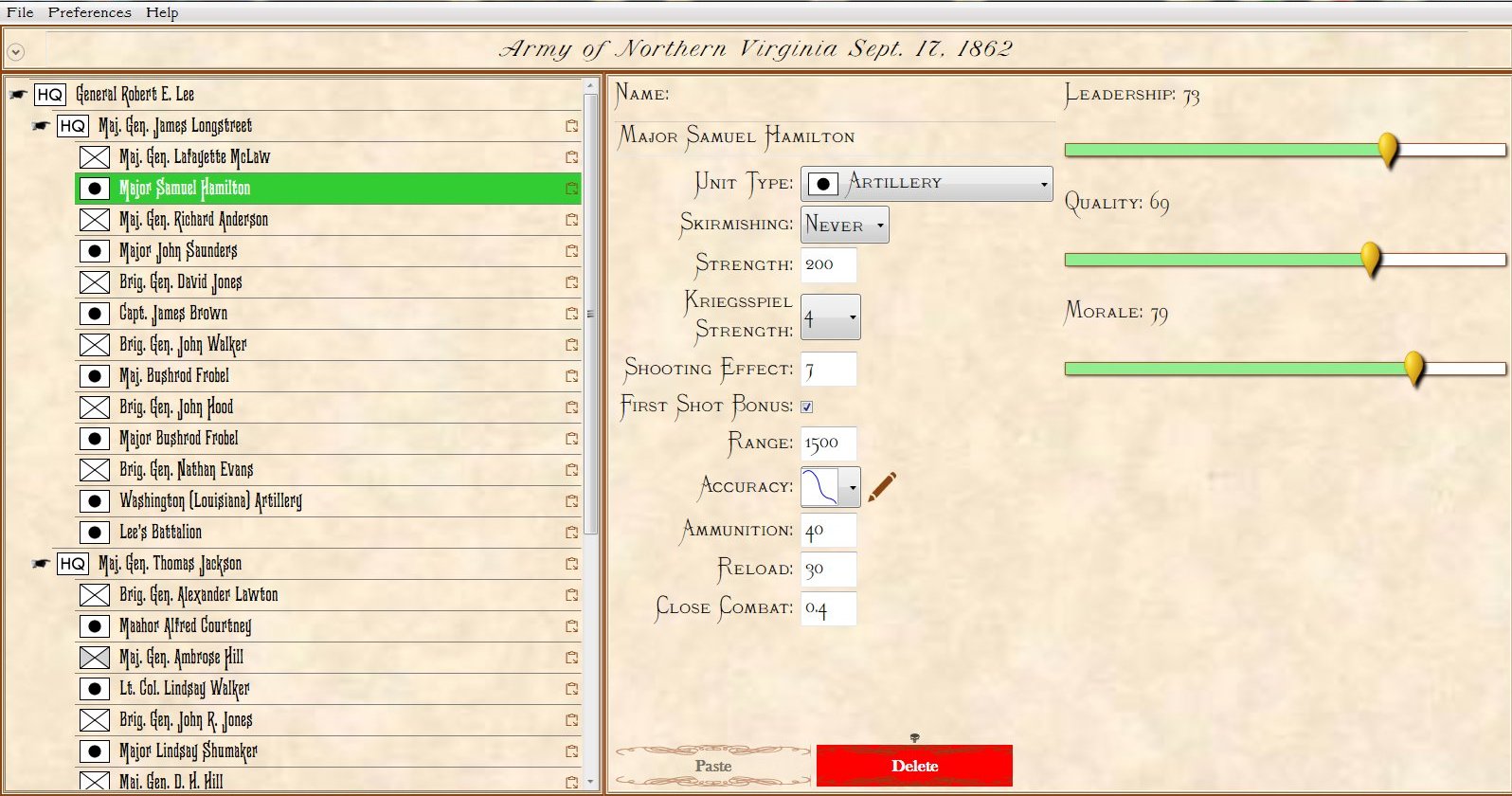
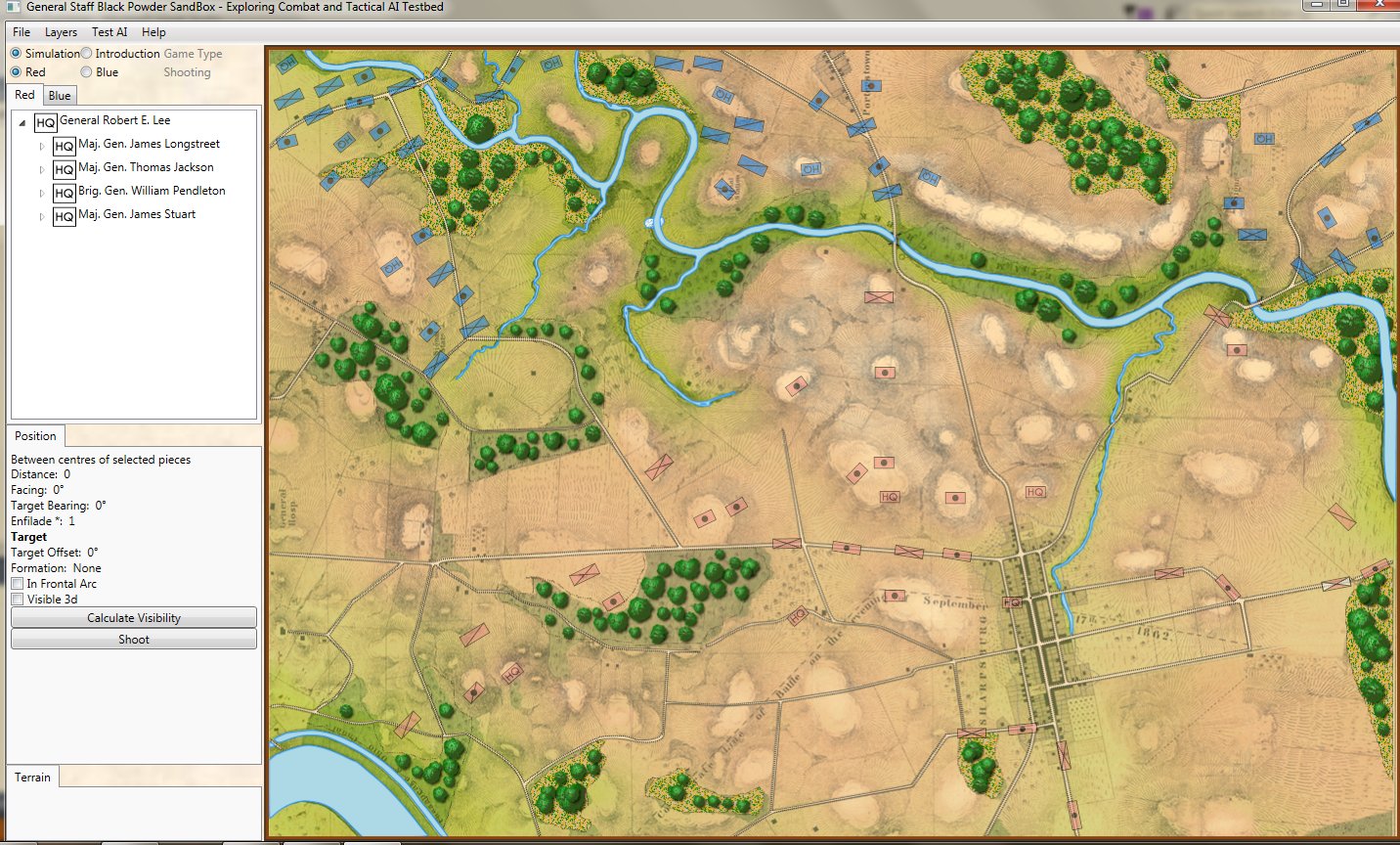
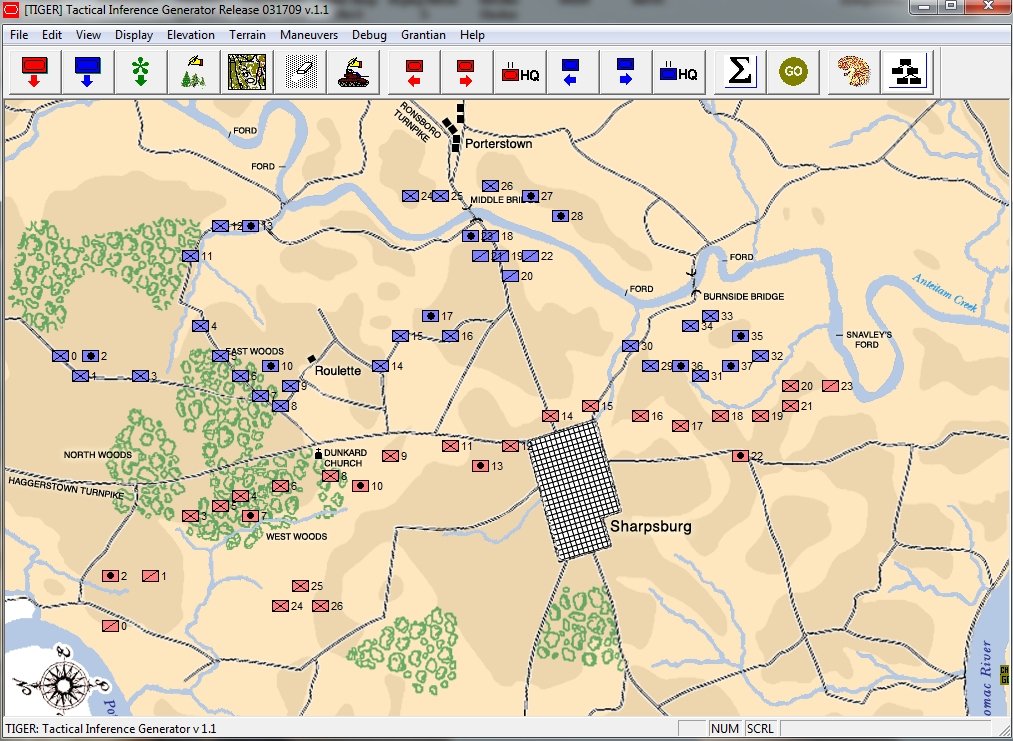
Order of Battle for Antietam showing Hamilton’s battery being edited. Screen shot from the General Staff Army Editor. Click to enlarge.
In the above image we are editing a Confederate battery in Longstreet’s corps. Every unit can have a unique unit range and accuracy. You can select an accuracy curve from the drop-down menu or you can create a custom accuracy curve by clicking on the pencil (Edit) icon.
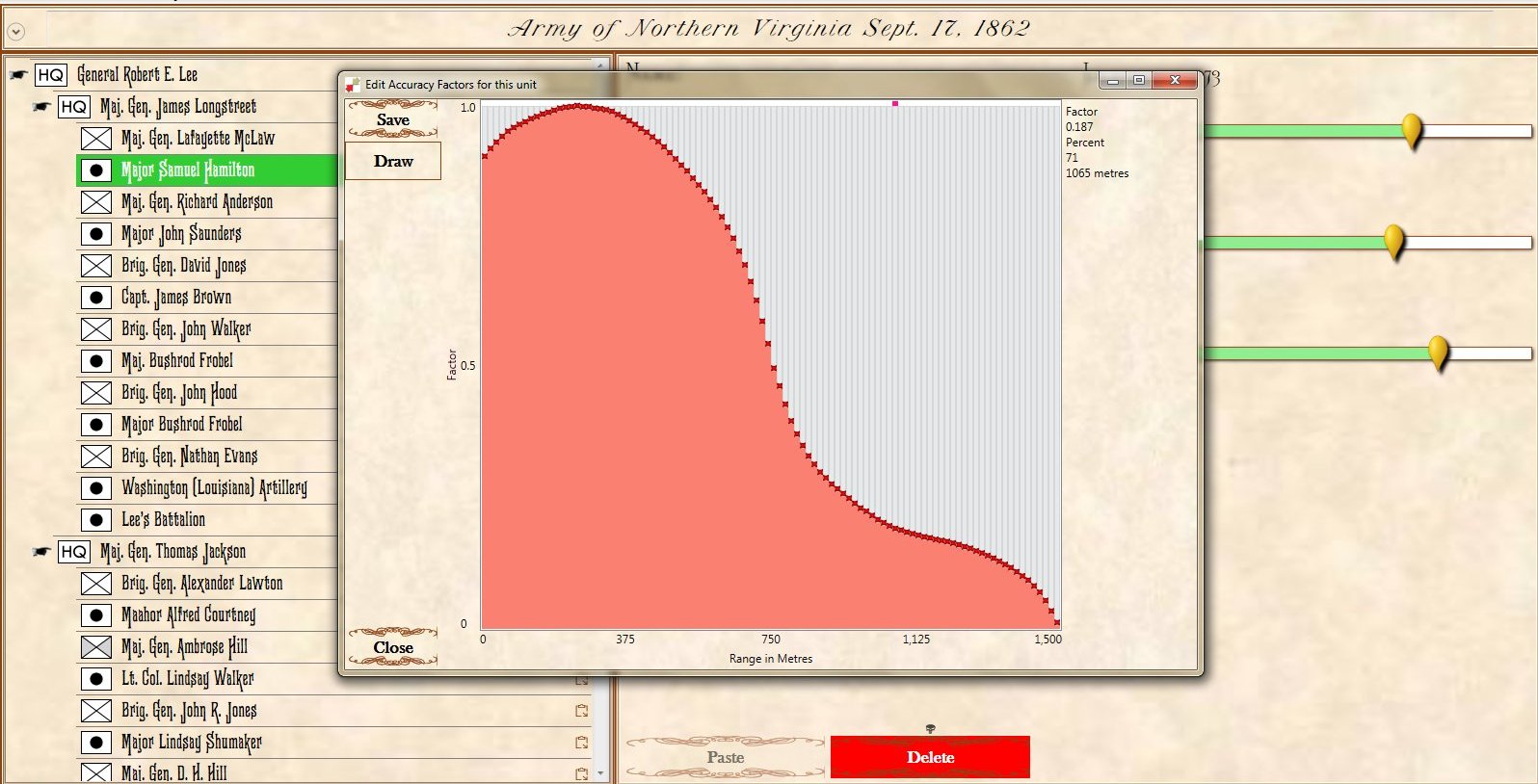
Window for editing the artillery accuracy curve. There are 100 points and you can set each one individually. This also supports a digitizing pen and drawing tablet. Screen shot from General Staff Army Editor. Click to enlarge.
In the above screen shot from the General Staff Wargaming System Army Editor the accuracy curve for this particular battery is being edited. There are 100 points that can be edited. As you move across the curve the accuracy at the range is displayed in the upper right hand corner. Note: every unit in the General Staff Wargaming System can have a unique accuracy curve as well as range and every other variable.
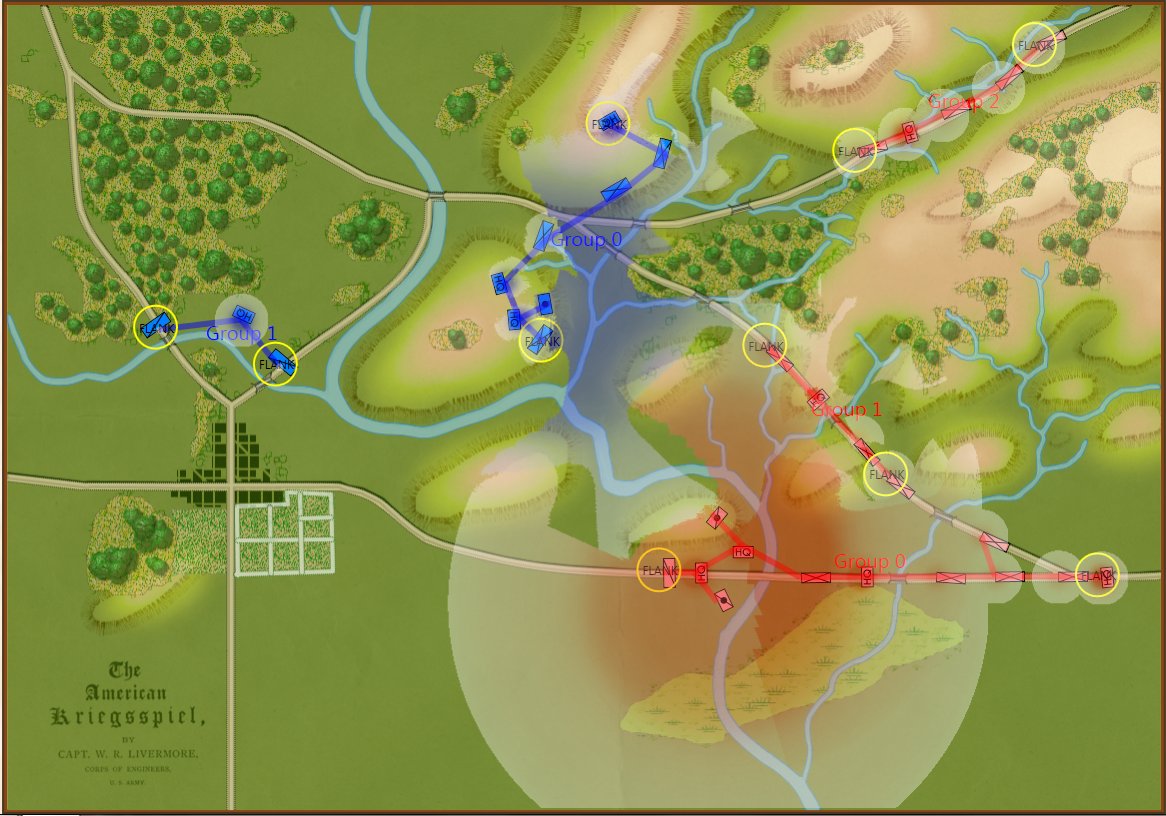
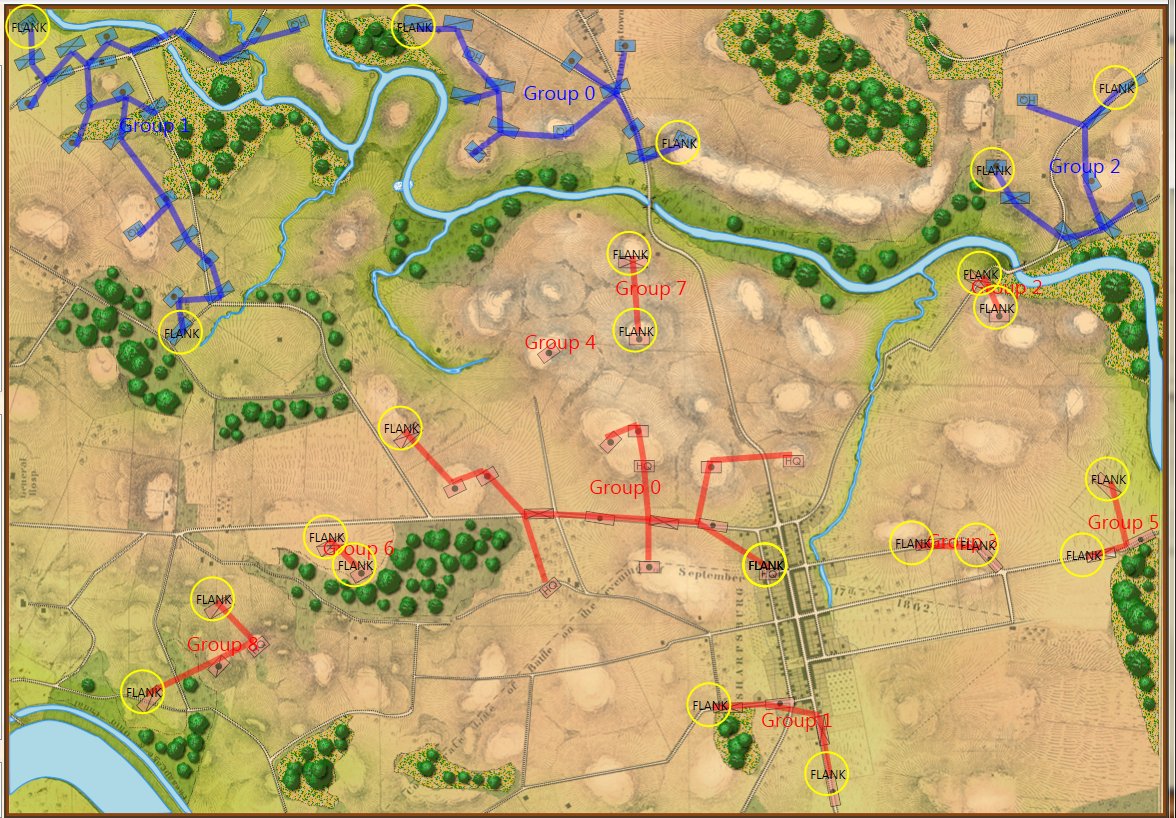
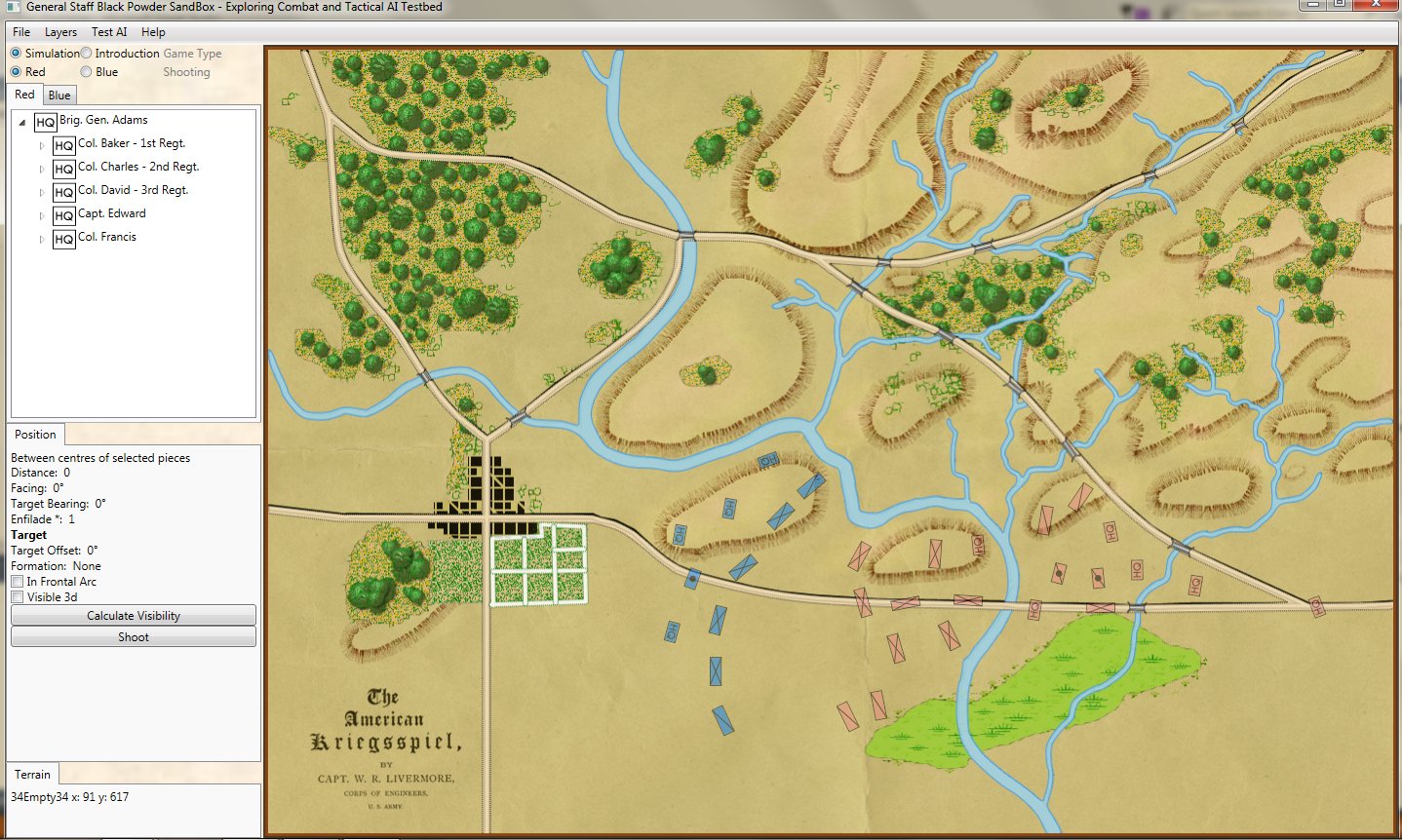
Screen shot showing the Range of Influence fields for a scenario from the 1882 American Kriegsspiel book. Click to enlarge.
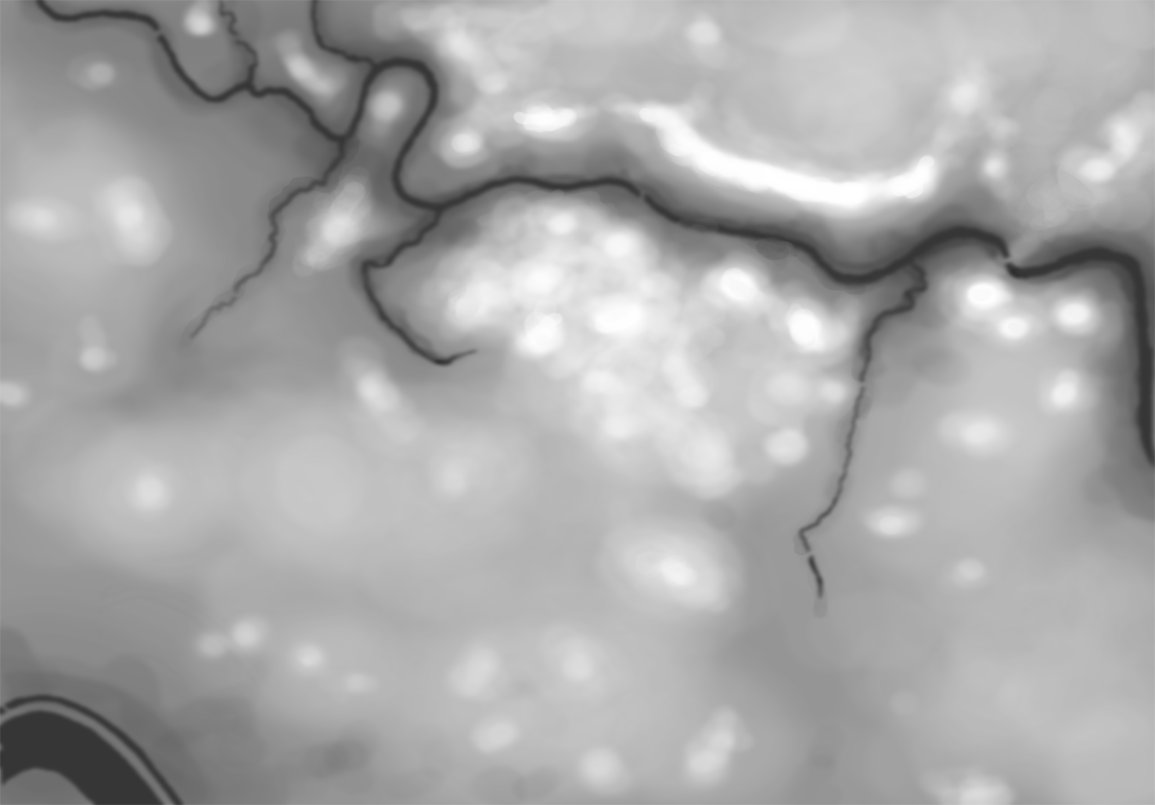
In the above screen shot from the General Staff Sand Box (which is used to test AI and combat) we see the ROI for a rear guard scenario from the original American Kriegsspiel 1882. Notice that the southern-most Red Horse Artillery unit has a mostly unobstructed field of vision and you can clearly see how accuracy diminishes as range increases. Also, notice how the ROI for the one Blue Horse Artillery unit is restricted by the woods which obstructs its line of sight.
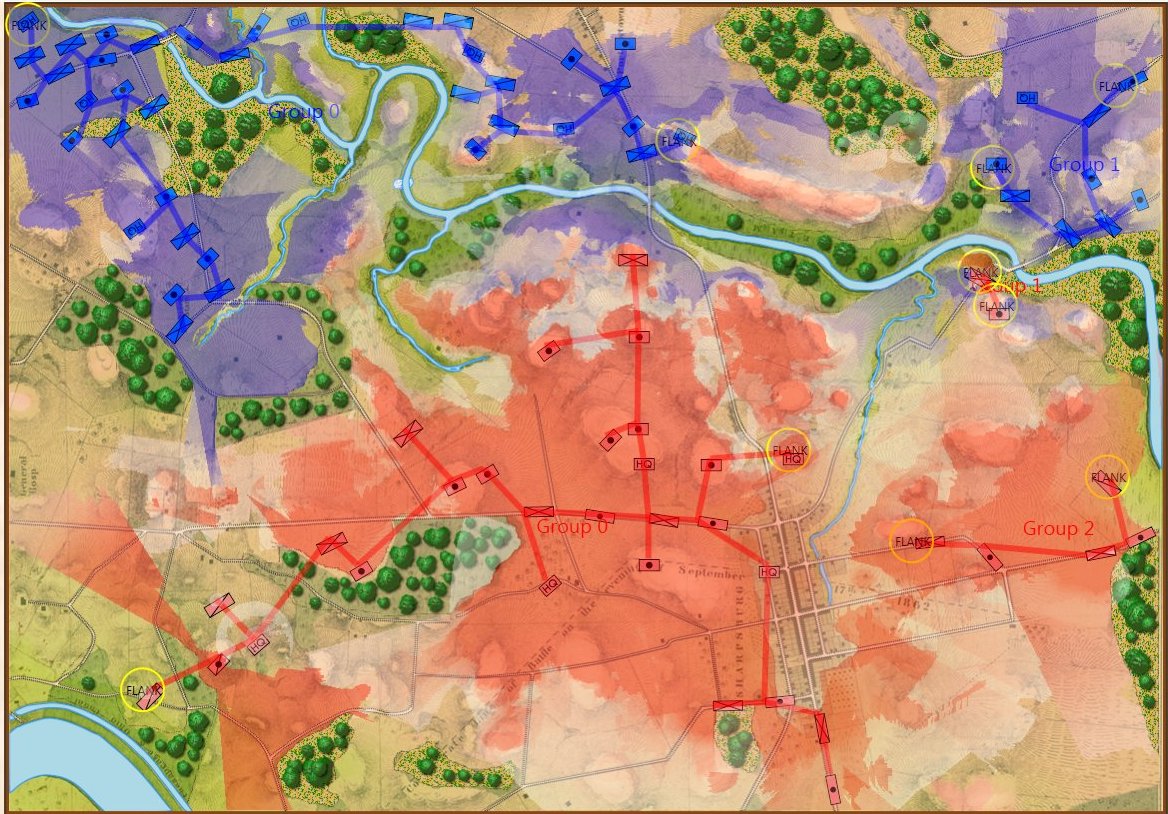
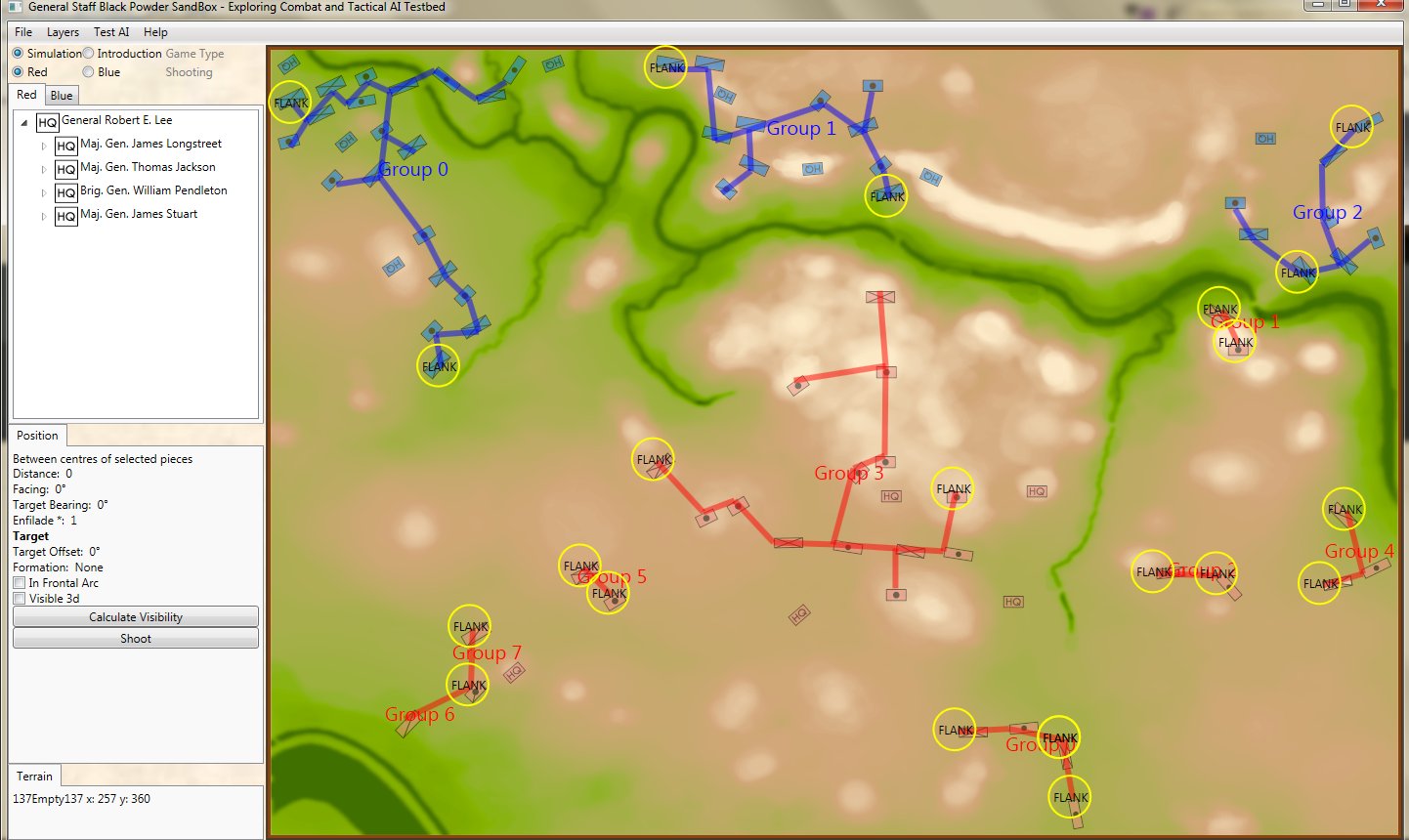
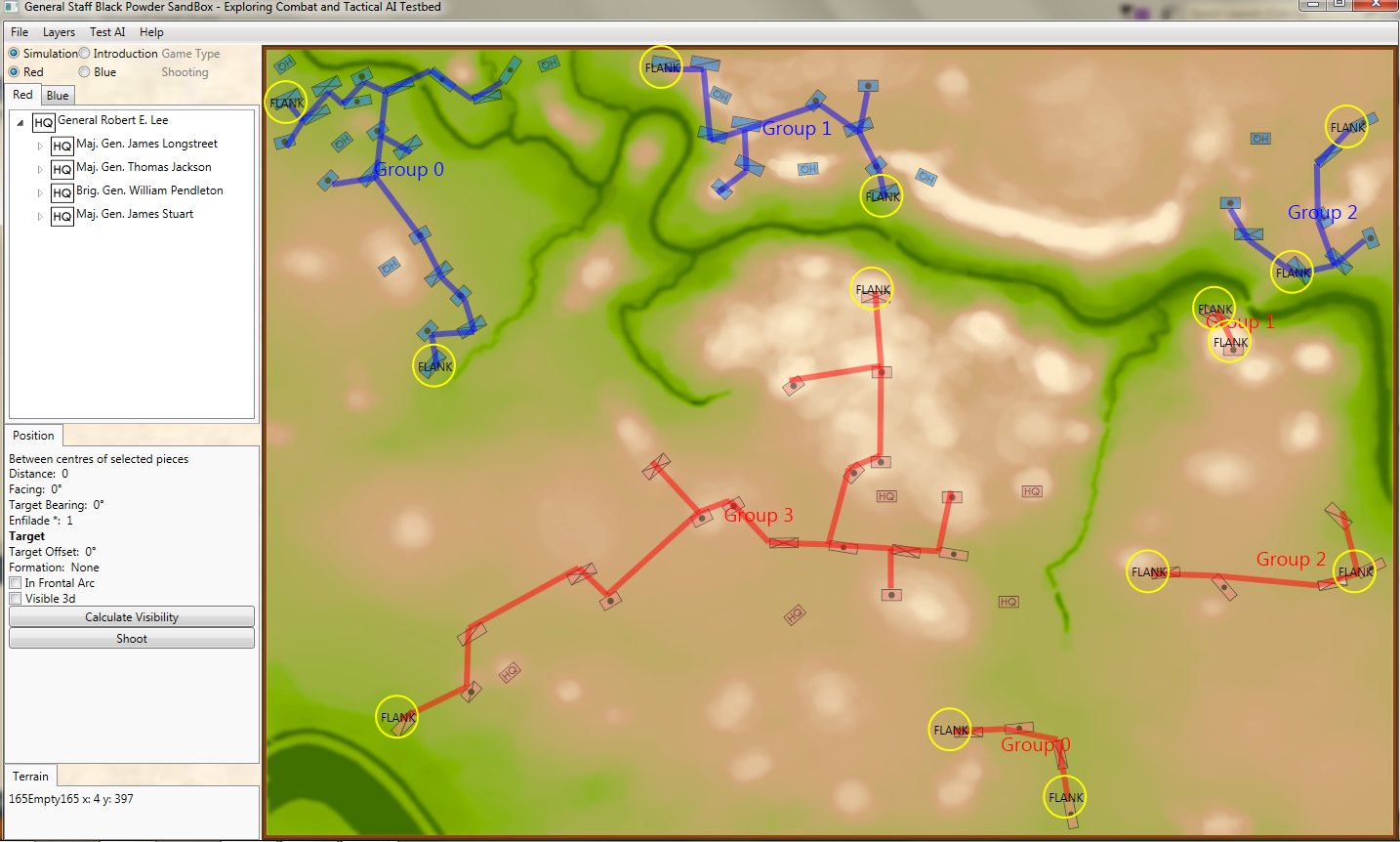
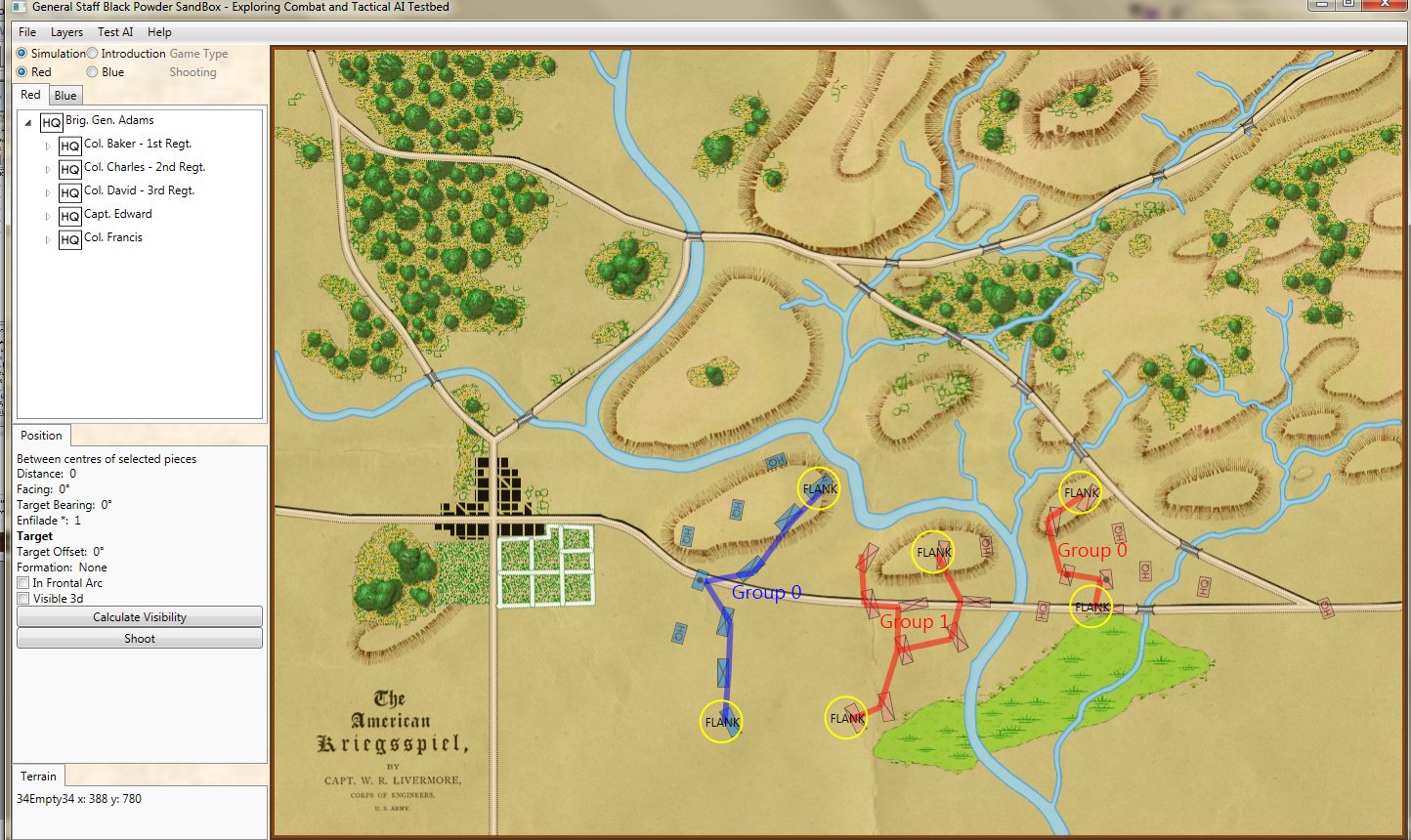
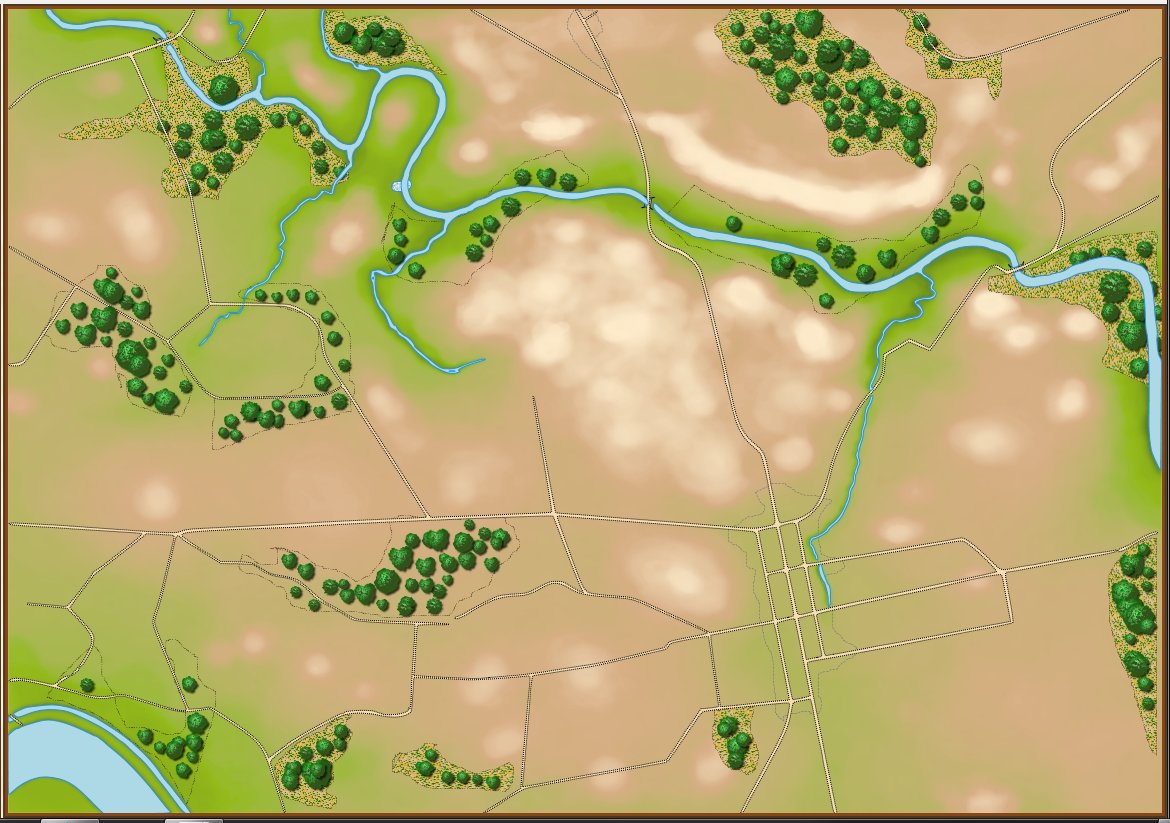
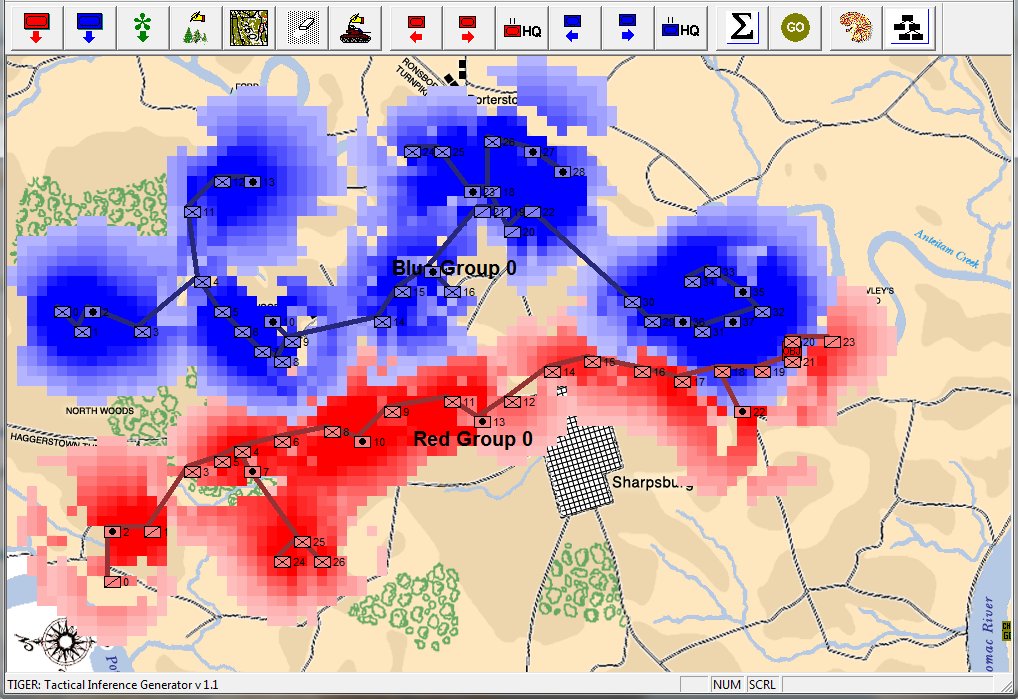
Screen shot of Antietam (dawn) showing Red and Blue ROI and battle lines. Click to enlarge.
In the above screen shot we see the situation at Antietam at dawn. Blue and Red units are rushing on to the field and establishing battle lines. Again, notice how terrain and elevation effects ROI. In the above screen shot Blue artillery’s ROI is restricted by the North Woods.
The above ROI maps (screen shots) were created by the General Staff Sand Box program to visually ‘debug’ the ROI (confirm that it’s working properly). We probably won’t include this feature in the actual General Staff Wargame unless users would like to see it added.
This is a topic that is very near and dear to my heart. Please feel free to contact me directly if you have any questions or comments.