
I coined the phrase ‘computational military reasoning’ in grad school to explain what my doctoral thesis in computer science was about. ‘Computational reasoning’ is a formal method for solving problems (technically, you don’t even need a computer). But, for our purposes it means a computer solving ‘human-level’ problems. A classic example of this would be calculating the fastest route on a map between two points. In computer science we call this a ‘least weighted path’ algorithm and I did my Q (Qualifying) Exam on this subject. I have also written extensively on the subject including these blog posts.
So, ‘computational military reasoning’ is a, “computer solving human-level military problems.” Furthermore, we can divide computational military reasoning into two subcategories: strategic and tactical (Russian military dogma also adds a third category, ‘grand strategy’); however, for now, let’s concentrate on tactical artificial intelligence; or battlefield decisions.
Tactical AI is divided into two parts: analyzing – or reading – the battlefield and acting on that information by creating a set coherent orders (commonly known as a COA or Course of Action) that exploit the weaknesses in our enemy’s position that we have found during our battlefield analysis.

It is said that as Napoleon traveled across Europe with his staff he would question them about the terrain that they were passing; “Where is the best defensive position? What are the best attack routes?” Where would you position artillery? What ground is favorable for cavalry attack?”
We take it for granted that such analysis of terrain and opposing forces positioned upon it is a skill that can be taught to humans. My doctoral research 1)TIGER: An Unsupervised Machine Learning Tactical Inference Generator; This thesis can be downloaded free of charge here. successfully demonstrated the hypothesis that an unsupervised machine learning program could also learn this skill and perform battlefield analysis that was statistically indistinguishable2)Using a one sided Wald test resulted in p = 0.0001.In other words, it was extremely unlikely that TIGER was ‘guessing correctly’. from analyses performed by Subject Matter Experts (SMEs) such as instructors at West Point and active duty combat command officers.
Supervised & Unsupervised Machine Learning
Netflix recommendations are a supervised learning program. Every time you ‘like’ a movie the program ‘learns’ that you like ‘documentaries’; for example. Any program that has you ‘like’ or ‘dislike’ offerings is a supervised learning program. You are the supervisor and by clicking on ‘like’ or ‘dislike’ you are teaching the program.
TIGER is an unsupervised machine learning program. That means it has to figure everything out for itself. Rather than being taught, TIGER is ‘fed’ a series of ‘objects’ that have ‘attributes’ and it sorts them into like categories. For TIGER the objects are snapshots of battlefields.
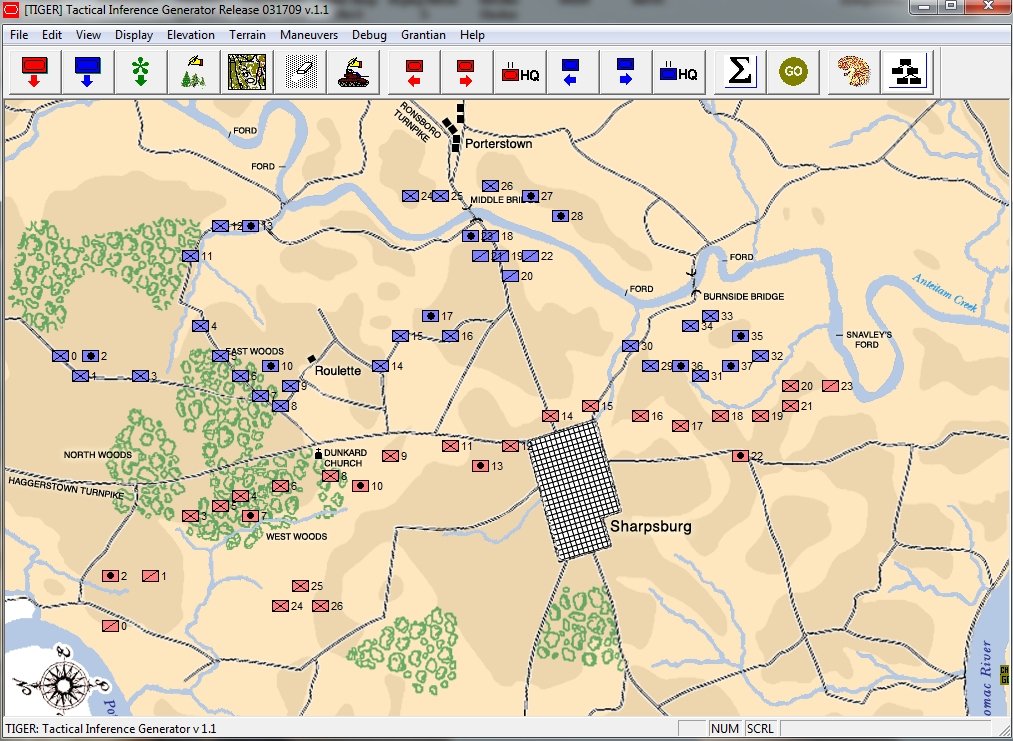
Screen capture from TIGER. An ‘object’ has been loaded into TIGER for analysis; in this case a ‘snapshot’ of the battle of Antietam at 1630 hours on September 17, 1863. Click to enlarge.
How TIGER perceives the battlefield
When you and I look at a battlefield our brains, somehow, make sense of all the NATO 2525B icons scattered around the topographical map. I don’t know how our brains do it, but this is how TIGER does it:
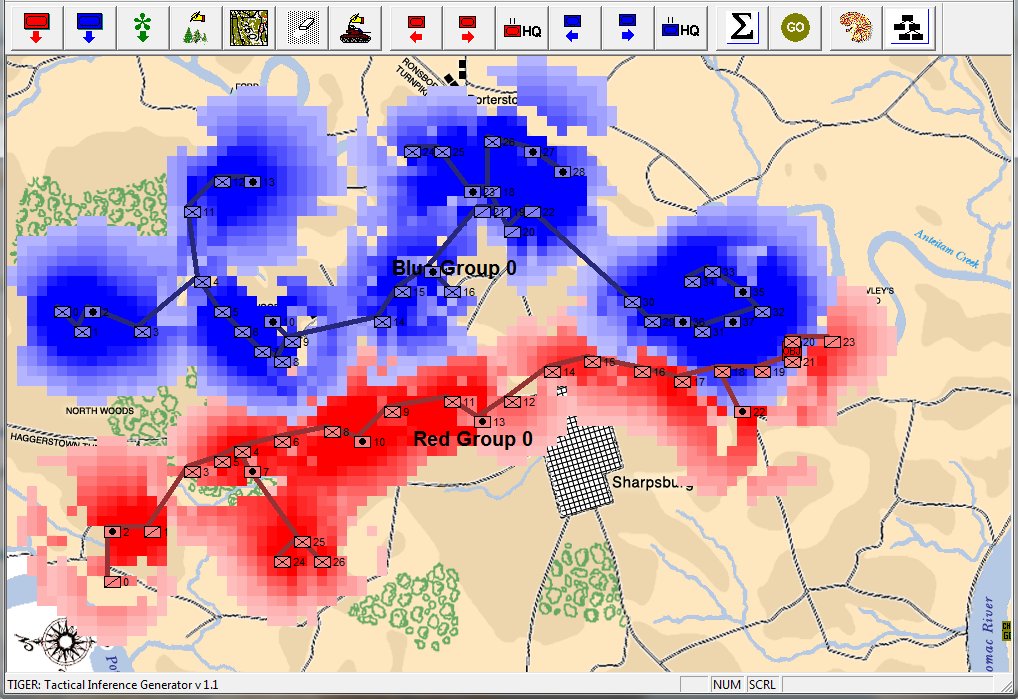
Screen capture from TIGER: How TIGER converts unit positions into lines and frontages using a Minimum Spanning Tree (MST). Click to enlarge.
By combining 3D Line of Sight with Range of Influence (how far weapons can fire and how accurate they are at greater distances displayed, above, with lighter colors) with a Minimum Spanning Tree algorithm3)Kruskal’s algorithm, https://en.wikipedia.org/wiki/Kruskal%27s_algorithm the above image is how TIGER ‘sees’ the battlefield of Antietam. This is an important first step for evaluating object attributes.
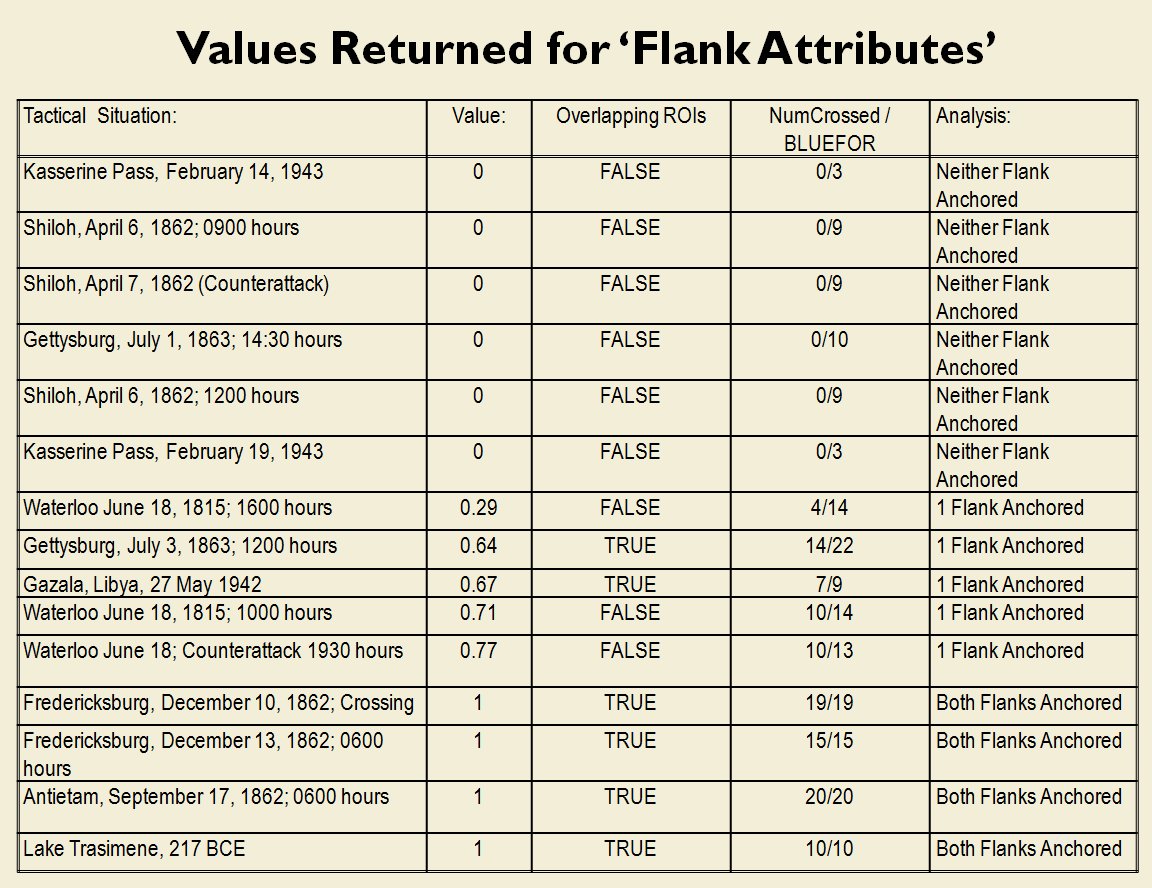
How to determine the attribute of anchored or unanchored flanks
Battlefields are ‘objects’ that are made up of ‘attributes’. One of these attributes is the concept of anchored and unanchored flanks. While anyone who plays wargames probably has a good idea what is meant by a ‘flank’, following formal scientific methods I had to first prove that there was agreement among Subject Matter Experts (SMEs) on the subject. This is from one of the double-blind surveys given to SMEs:
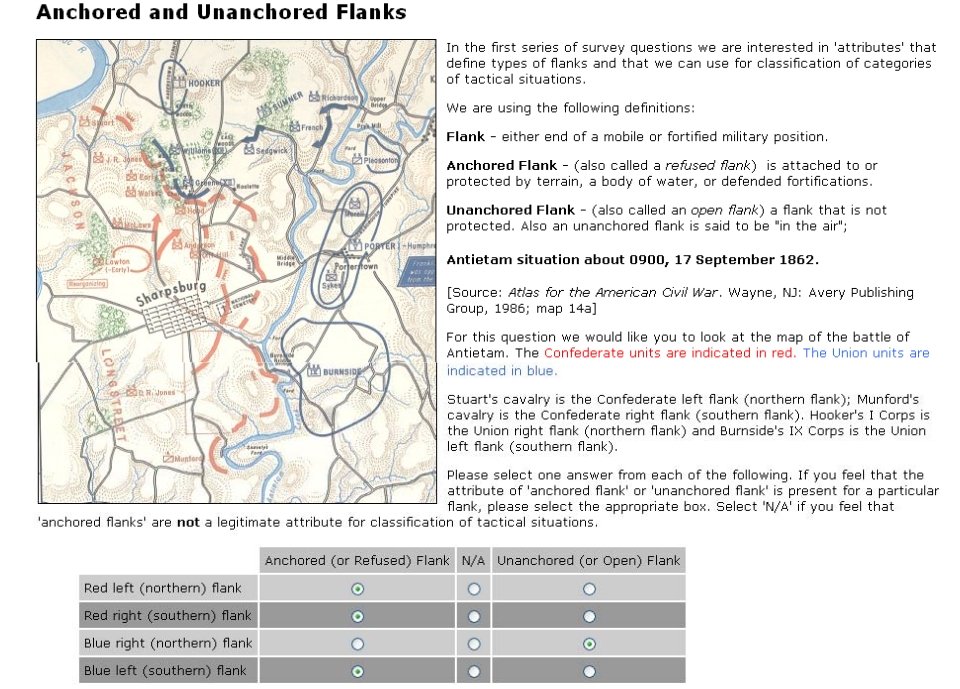
Screen shot from online double-blind survey of Subject Matter Experts on identifying the presence of Anchored and Unanchored Flanks. Click to enlarge.
And their responses to the situation at Antietam:
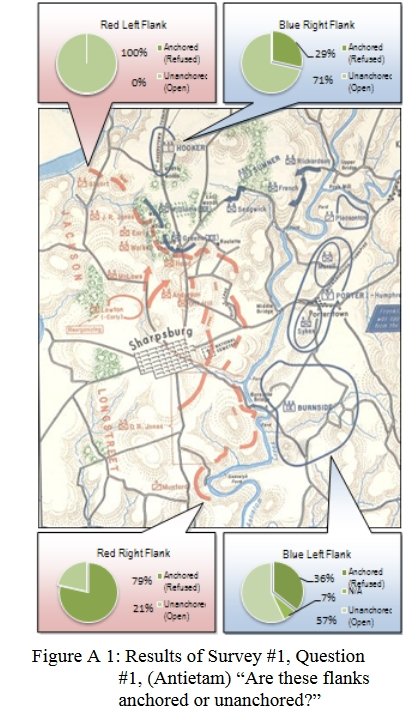
Subject Matter Experts response to the question of the presence of Anchored or Unanchored flanks at Antietam. Click to enlarge.
And another double-blind survey question asked of the SMEs about anchored or unanchored flanks at Chancellorsville:
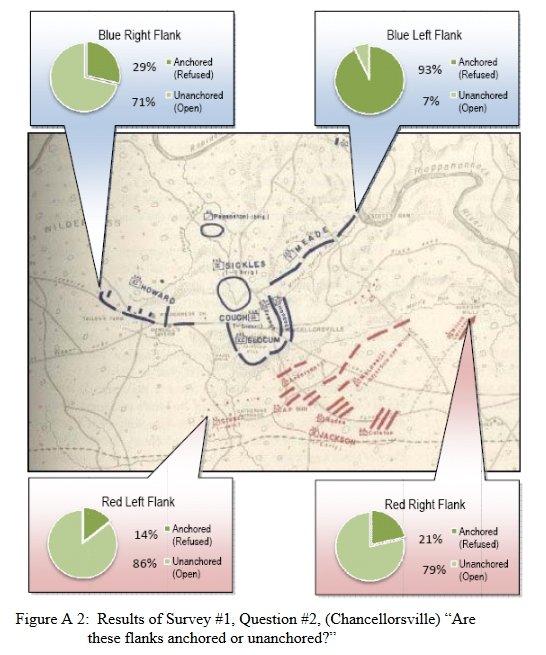
Response to double-blind survey question asked of SMEs about anchored and unanchored flanks at Chancellorsville. Click to enlarge.
So, we have now proven that there is agreement among Subject Matter Experts about the concept of ‘anchored’ and ‘unanchored’ flanks and, furthermore, some battlefields exhibit this attribute and others don’t.
Following is a series of slides from a debriefing presentation that I gave to DARPA (Defense Advanced Research Projects Agency) as part of my DARPA funded research grant (W911NF-11-200024) describing the algorithm that MATE (the successor to TIGER) uses to calculate if a flank is anchored or unanchored and how to tactically exploit this situation with a flanking maneuver. This briefing is not classified. Click to enlarge slides.
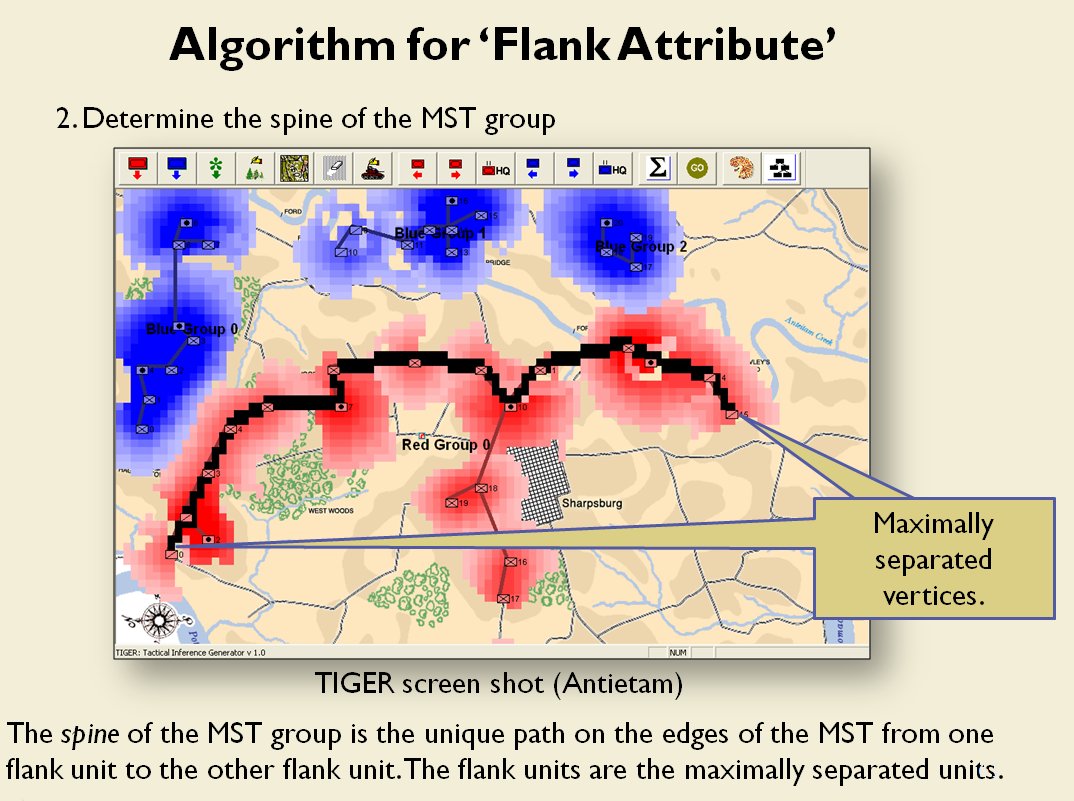
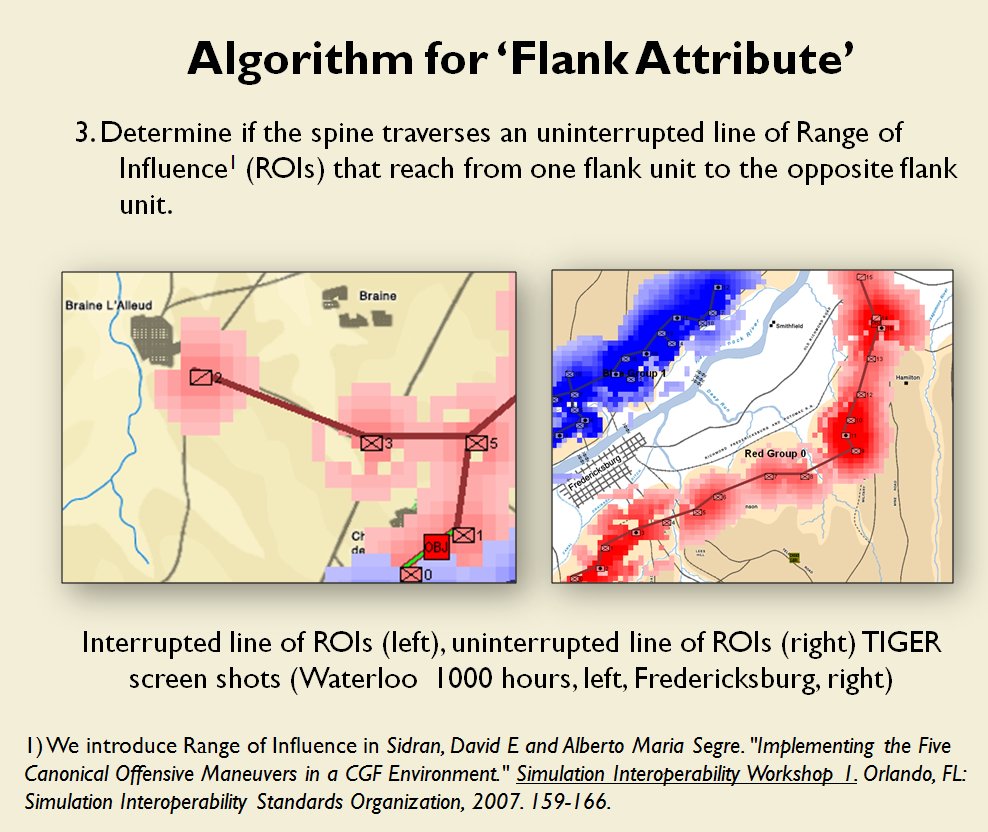
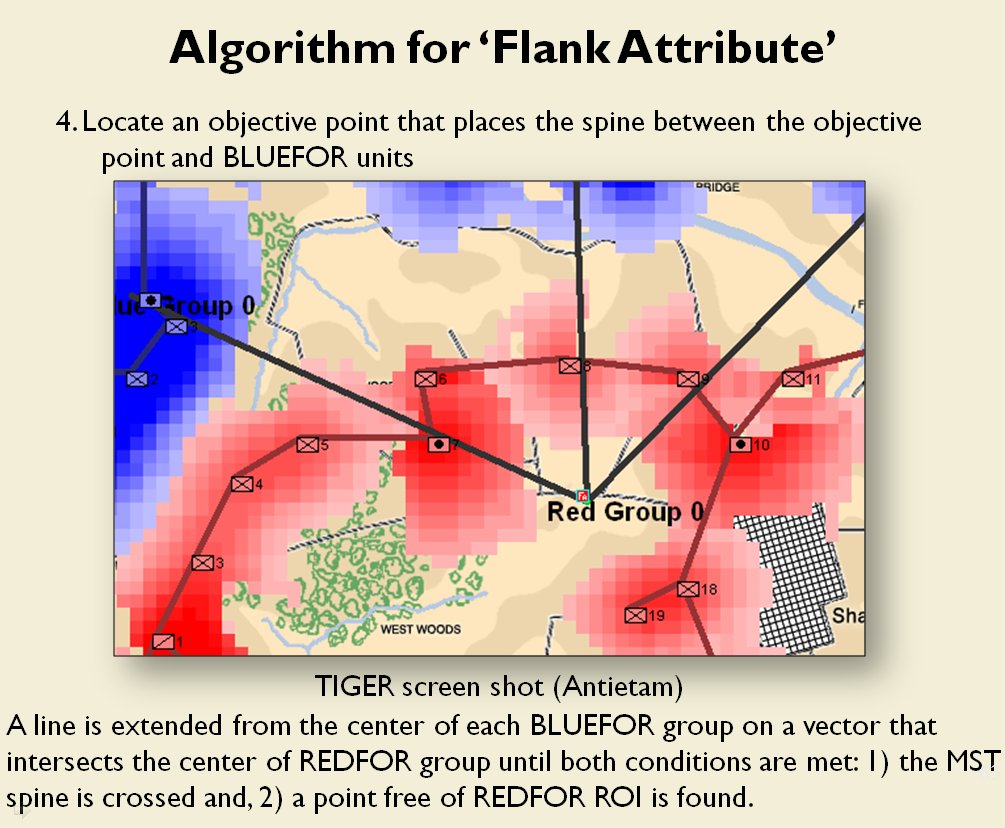
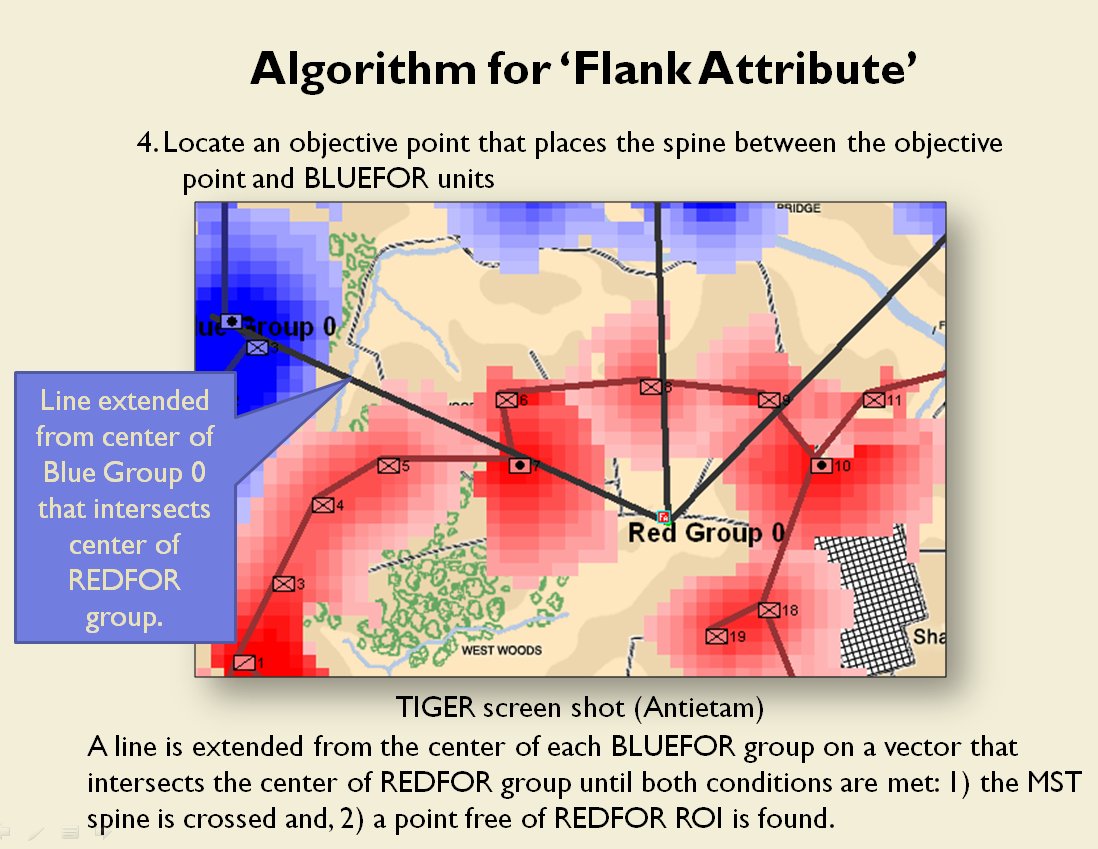
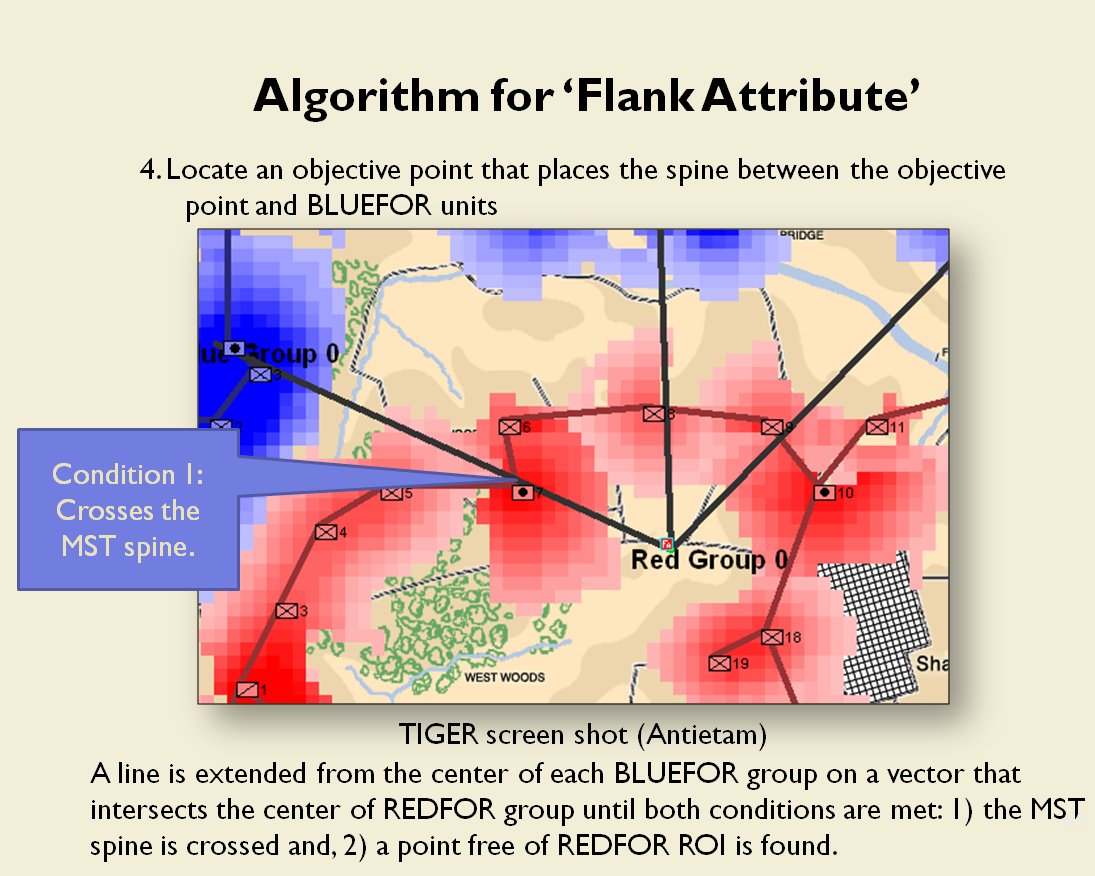
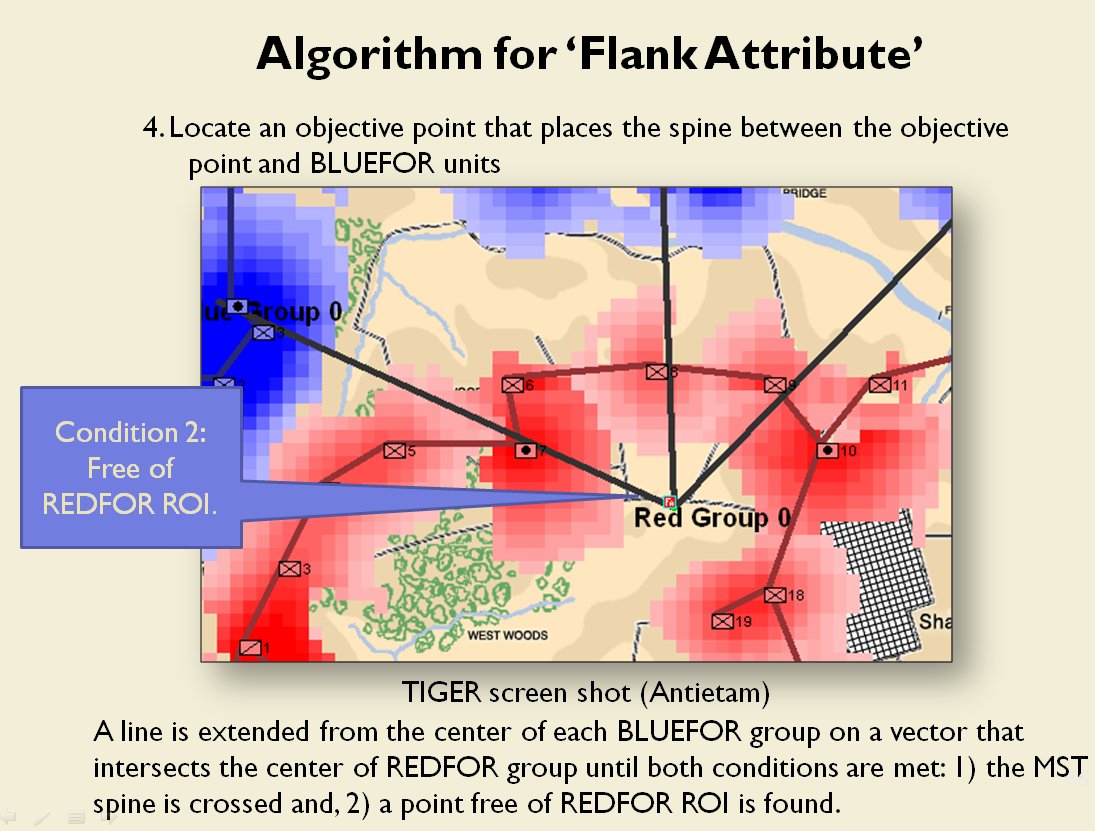
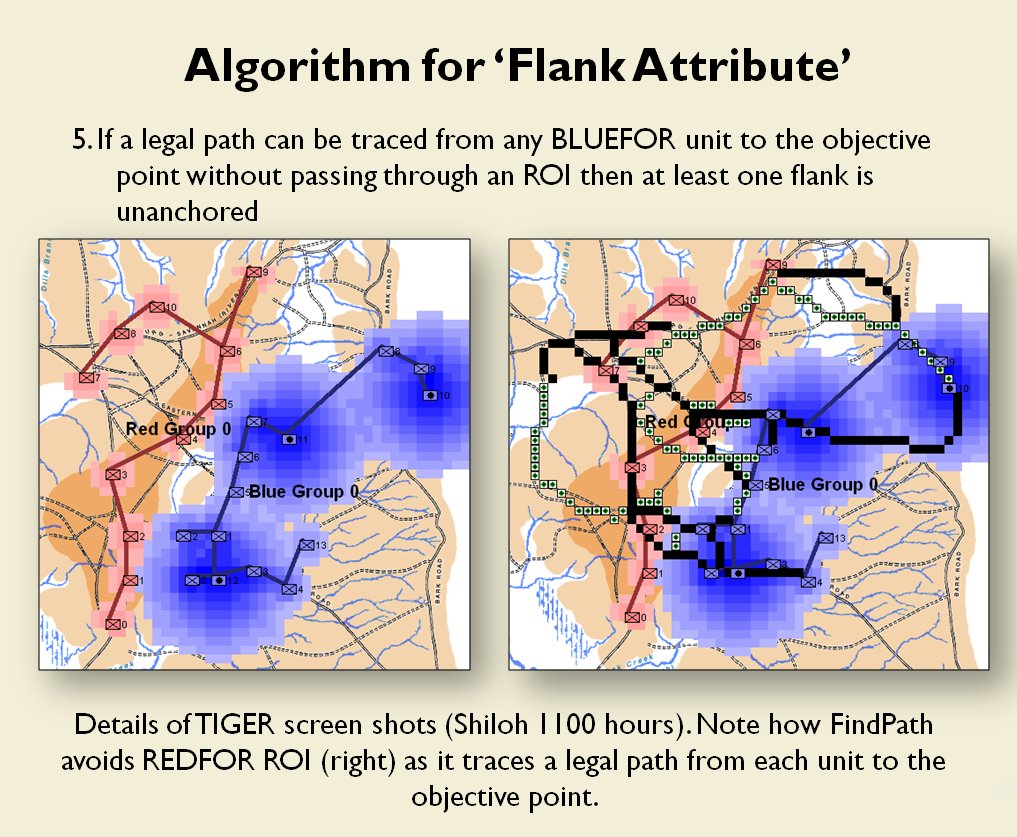

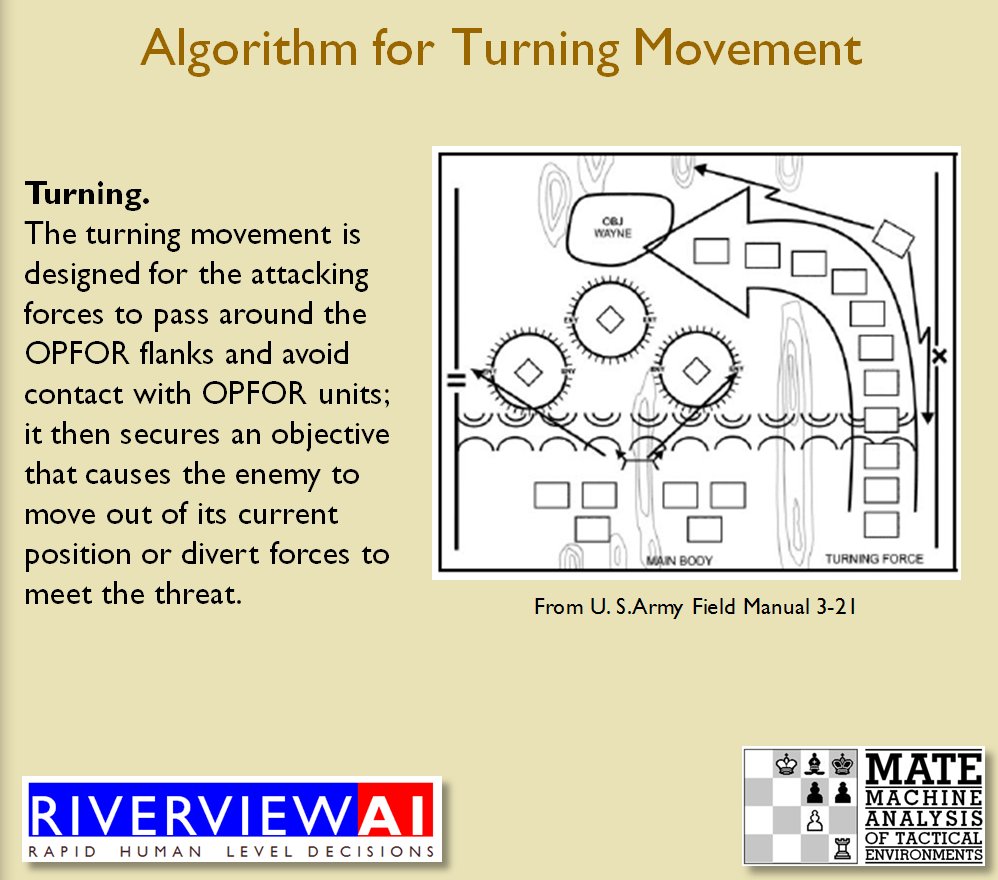
![]() How to generate a Course of Action for a flank attack
How to generate a Course of Action for a flank attack
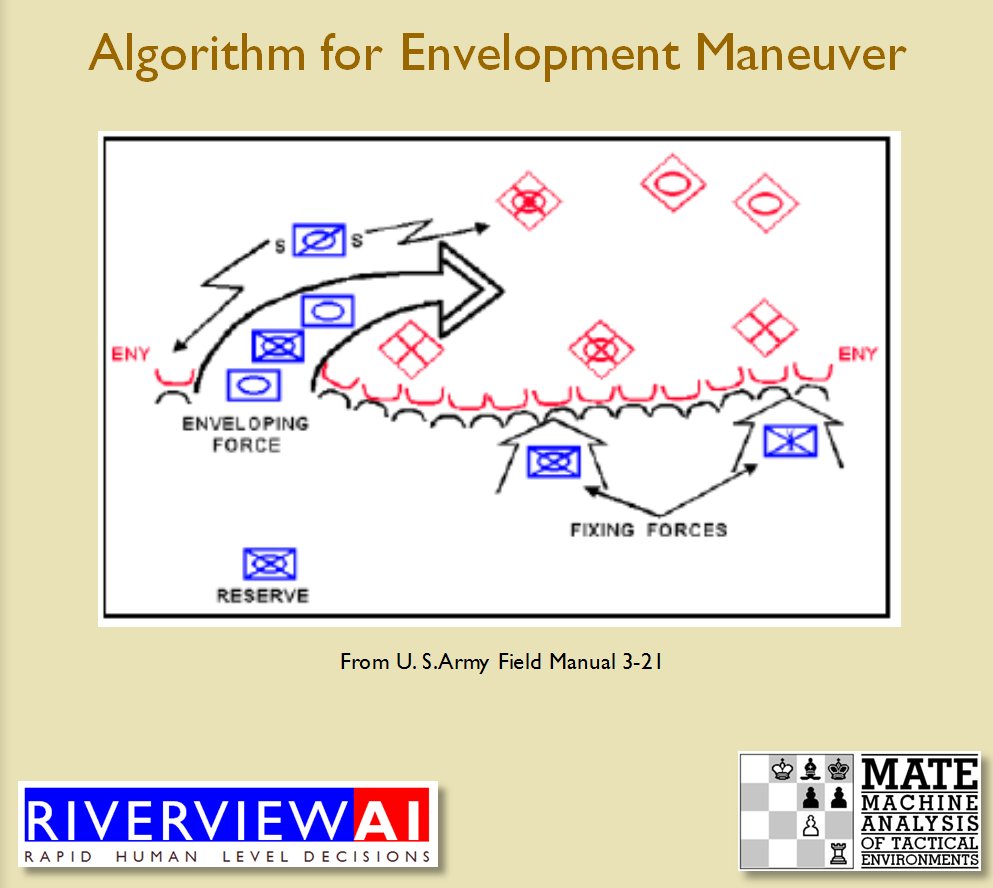
Once TIGER / MATE has detected an ‘open’ or unanchored flank it will then plot a Course of Action (COA) to maneuver its forces to perform either a Turning Maneuver or an Envelopment Maneuver. Returning to the previous DARPA debriefing presentation (Click to enlarge):

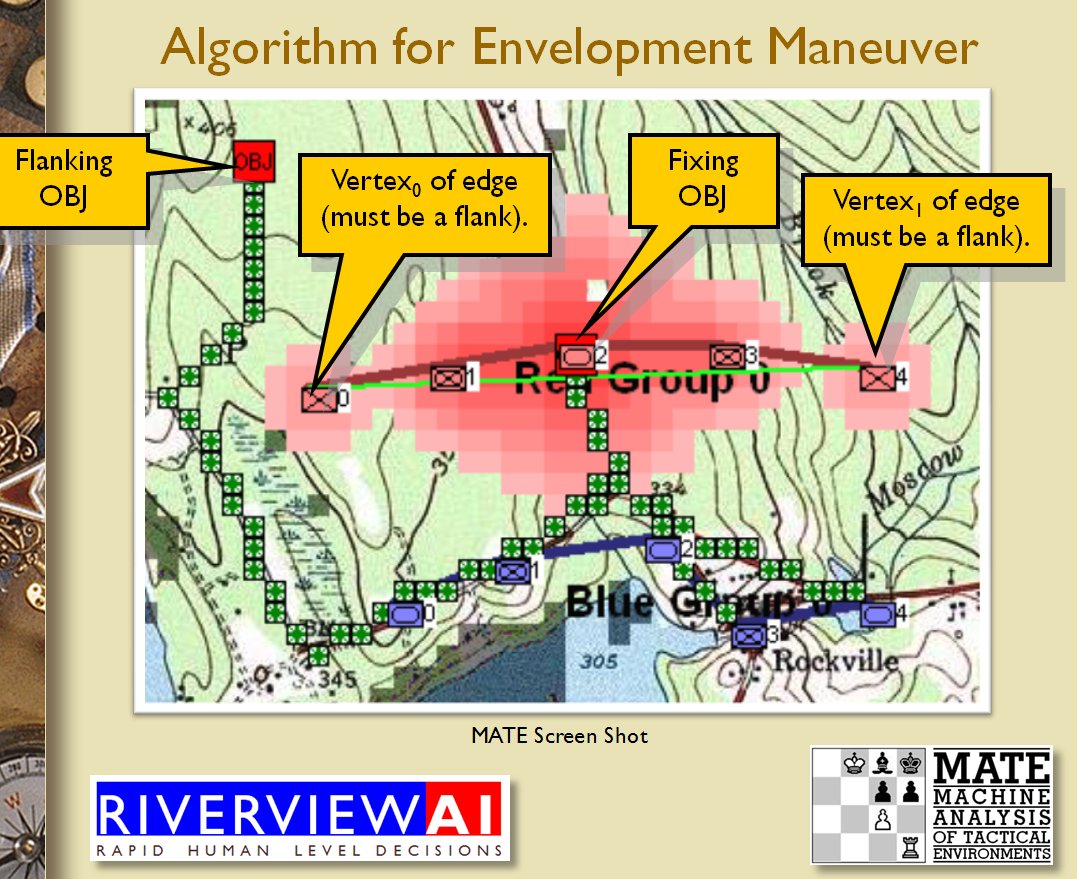
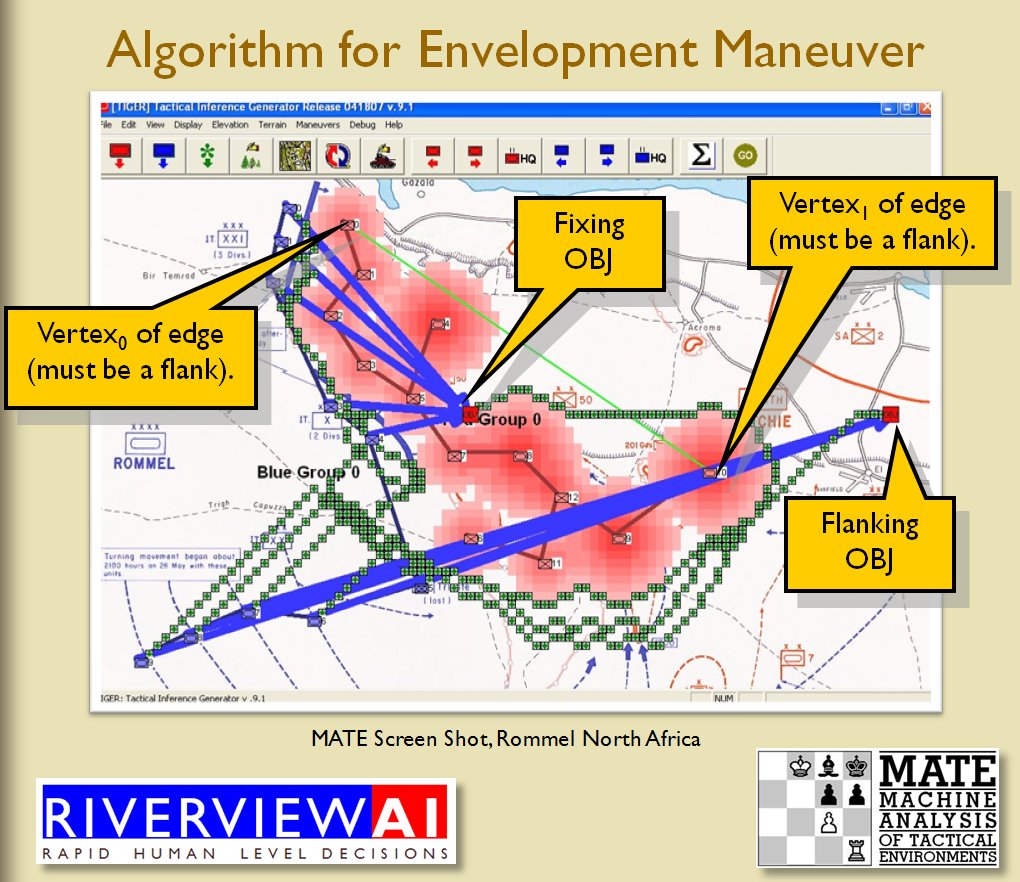



MATE analysis of the battle of Marjah (Operation Moshtarak February 13, 2010)
The following two screen captures are part of MATE’s analysis of the battle of Marjah suggesting an alternative COA (envelopment maneuver) to the direct frontal assault that the U. S. Marine force actually performed at Marjah. Click to enlarge:
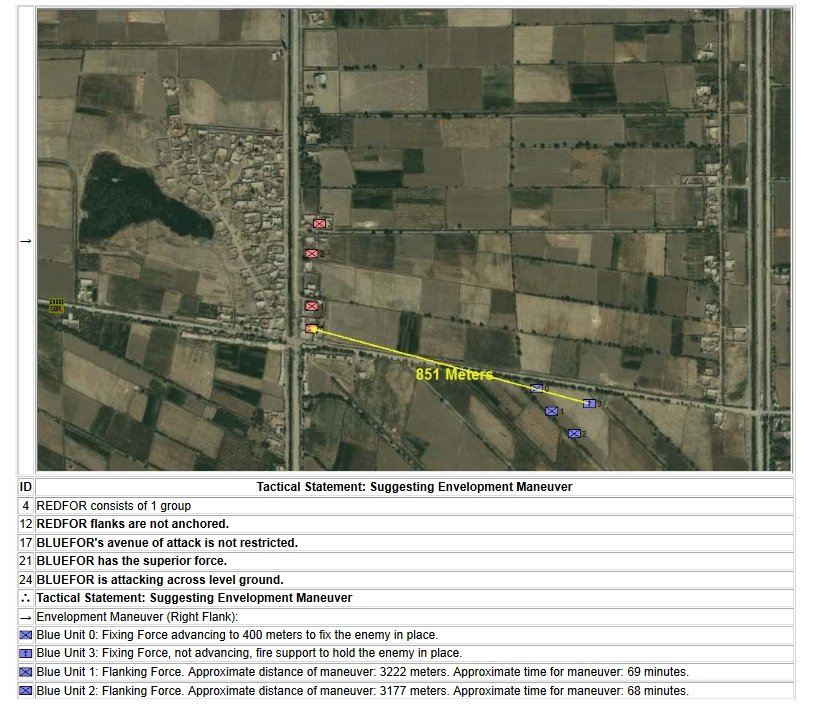
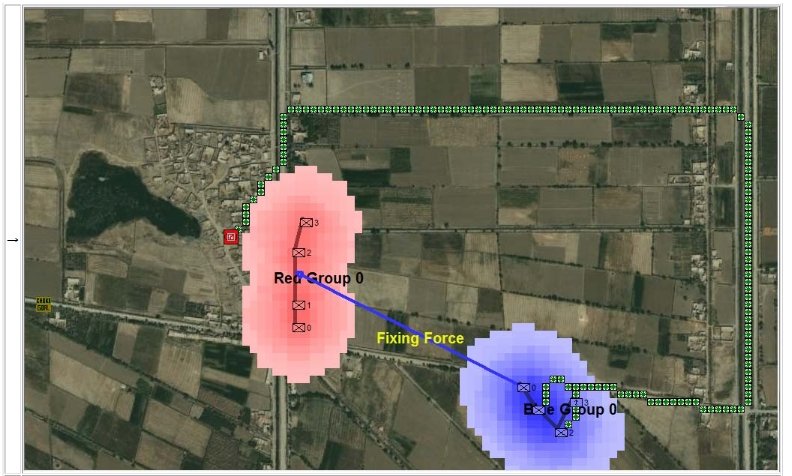
Conclusions & Comments about Computational Military Reasoning (Tactical Artificial Intelligence) & Battlefield Analysis (Part 1)
Usually, at this point when I give this lecture, I look out to my audience and ask for questions. I really don’t want to lose anybody and we’ve got a lot more Tactical AI to talk about. So far, I’ve only covered how my programs (TIGER / MATE) analyze a battlefield in one particular way (does my enemy – OPFOR in military terms – have an exposed flank that I can pounce on?) and there is a lot more battlefield analysis to be performed.
It’s easy, as a computer scientist, to use computer science terminology and shorthand for explaining algorithms. But, I worry that the non computer scientists in the audience will not quite get what I’m saying.
Do you have any questions about this? If so, I would really like to hear from you. I’ve been working on this research for my entire professional career (see A Wargame 55 Years in the Making) and, frankly, I really like talking about it. As a TA said to me many years ago when I was an undergrad, “There are no stupid questions in computer science.” So, please feel free to write to me either using our built in form or by emailing me at Ezra [at] RiverviewAI.com
References
| ↑1 | TIGER: An Unsupervised Machine Learning Tactical Inference Generator; This thesis can be downloaded free of charge here. |
|---|---|
| ↑2 | Using a one sided Wald test resulted in p = 0.0001.In other words, it was extremely unlikely that TIGER was ‘guessing correctly’. |
| ↑3 | Kruskal’s algorithm, https://en.wikipedia.org/wiki/Kruskal%27s_algorithm |
Pingback: Wargamer Logbook: 23 February 2020 – Gringogamer
True story. Worst wargame I ever payed..EVER played..was your “War College”. Thanks for that.
Sorry you didn’t like it. Classic story: publisher pushed it out before it was ready.
Pingback: Computational Military Reasoning (Tactical Artificial Intelligence) Part 2 | General Staff
Very interesting read, Ezra, thanks very much for taking the time to collate this little talk / presentation.
There are at least two more posts on about the AI covering other attributes and algorithms for tactical maneuvers.
Hope you enjoy them.
I enjoyed them very much, and studied the papers with attention, Ezra. I find your approach very elegant, and easy to integrate with existing frameworks for planning, optimal control and reinforcement learning.
Maybe one day I will find the time to put these algorithms and ideas to work along my own research… not necessarily making games, though.
Cheers,
Miquel.
This was a very interesting read and I would like to learn more. I’m downloading your thesis as I write- can’t wait to read it!
Thank you very much! I have at least three more posts to write on the subject of AI covering Restricted Avenues of Attack / Retreat, Interior Lines and Unsupervised Learning. Please feel free to write to me if you have any questions.